Innovation can’t guarantee success, but it provides a competitive edge. In his book, “The Innovator’s Dilemma,” Clayton Christensen discusses how market leaders can fall to a new competitor when faced with technological disruptions.
His seminal theory emphasizes that large organizations often miss out on revolutionary technology because of the technical debt their legacy systems tend to accumulate.
Application modernization helps companies reduce tech debt and harness the power of disruptive innovations. Older systems often have out-of-date features and architectural designs. As a result, upgrading these applications becomes complex and risky.
Modernizing an application enables your team to re-architecture the design into distributed components. Consequently, modernized applications have reduced technical debt even when you upgrade them with new features regularly.
However, while attempting to modernize your legacy applications and reduce tech debt, you must consider several factors, like broken elements, security breaches, service disruptions, etc.
Therefore, approaching application modernization the right way becomes crucial for organizations of all scales.So let’s look at six successful stories by brands that aced application modernization and found a way to reduce tech debt efficiently.
How Twitter Ads leveraged application modernization and reduced tech debt
Twitter Ads, the advertisement platform of Twitter, deals with billions of ad engagement events that affect hundreds of aggregate metrics. The platform also includes a data analytics tool to equip users with all the relevant data about ad performances.
Twitter Ads provides tools, features, and dashboards aggregating millions of metrics per second in real time. Initially, the system was easily manageable with a limited number of users. However, as its user base grew and the market evolved, there were challenges of scale, flexibility, and tech debt.
Major challenge: Twitter’s in-house systems fell short in the face of evolving market trends
Earlier, Twitter Ads developed data transformation pipelines to process large chunks of information, handle user load, and provide insights to users. These data transformation pipelines initially ran on local data centers.
Then, massive input data from multiple sources was aggregated at Hadoop Distributed File System (HDFS) and processed through the Scalding data transformation pipelines.
However, with time, the original system behind the implementation of data transformation pipelines outgrew its capacity. So, the end user legacy system became expensive to operate and support large queries.
Besides the above issues, long-running jobs induced sporadic failures due to lower reliability. Further, Twitter Ads teams wanted to streamline new feature development and user engagement as per the predicted trends.
Solution: Re-architecting the design and deploying a flexible system in Google Cloud
In 2017, the Twitter Ad Revenue Engineering team decided to re-architect the design and create a flexible system on Google Cloud. Notably, it was not a single-shot re-architecture sprint but an iterative process.
Iteration 1 – The platform application modernization
In the first iteration, the team focused on output batch layer migration to Google Cloud storage locations like BigQuery and CloudBigTable. BigQuery is serverless storage by Google Cloud, and CloudBigTable is a fully-managed NoSQL database.
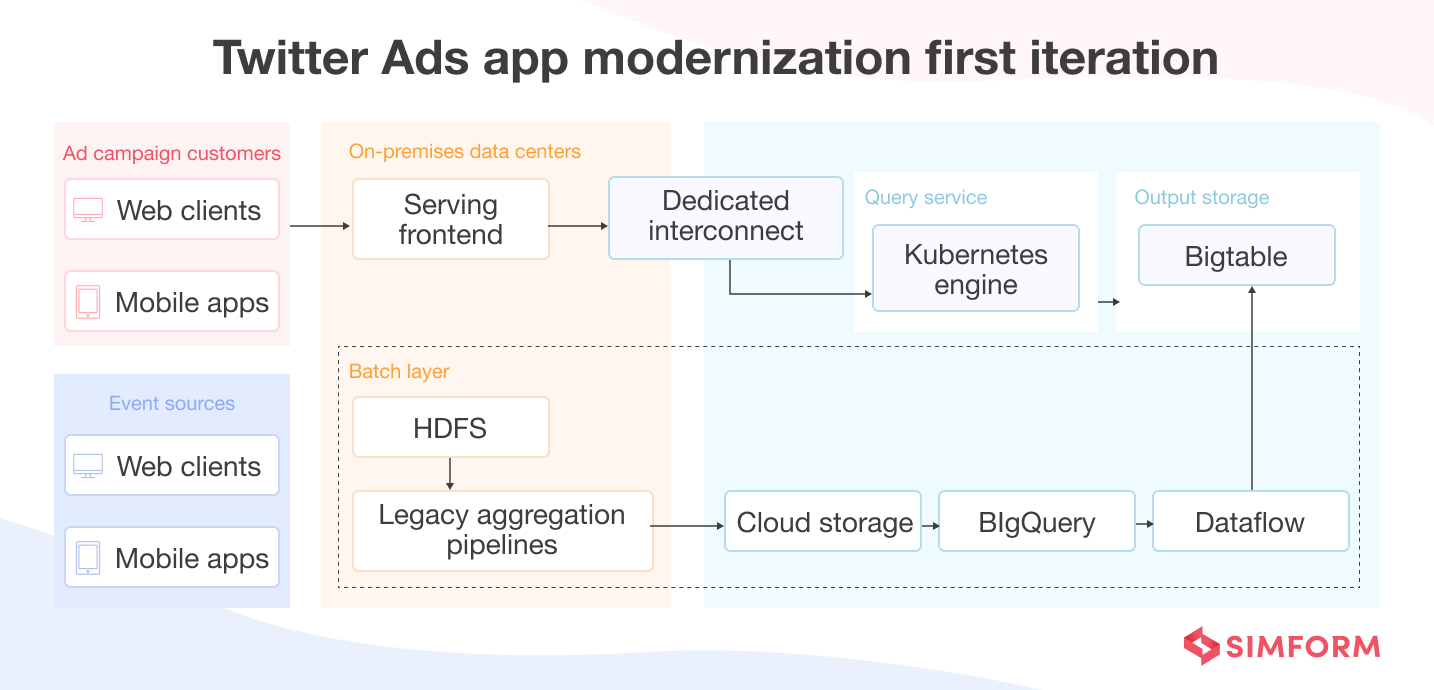
Earlier, Google’s fully-managed streaming and data analytics service (Dataflow) fetched the data from BigQuery and partially transformed them before storing them on the Bigtable. The Twitter Ads engineering team built a new query service that fetches the aggregated data values from the Bigtable and processes the end-user queries.
The team deployed this new query service on Google Kubernetes Engine (GKE) cluster in the same region as Bigtable to reduce data latency.
Iteration 2 – Resolution of HDFS aggregation issues
Despite the platform being majorly modernized, Twitter Ads engineers still needed to solve the HDFS aggregation issues, eliminate logic duplication, and reduce the cost of running the real-time layer. To achieve these objectives, they evaluated various open-source stream processing options, like Apache Flink, Apache Kafka Streams, and Apache Beam.
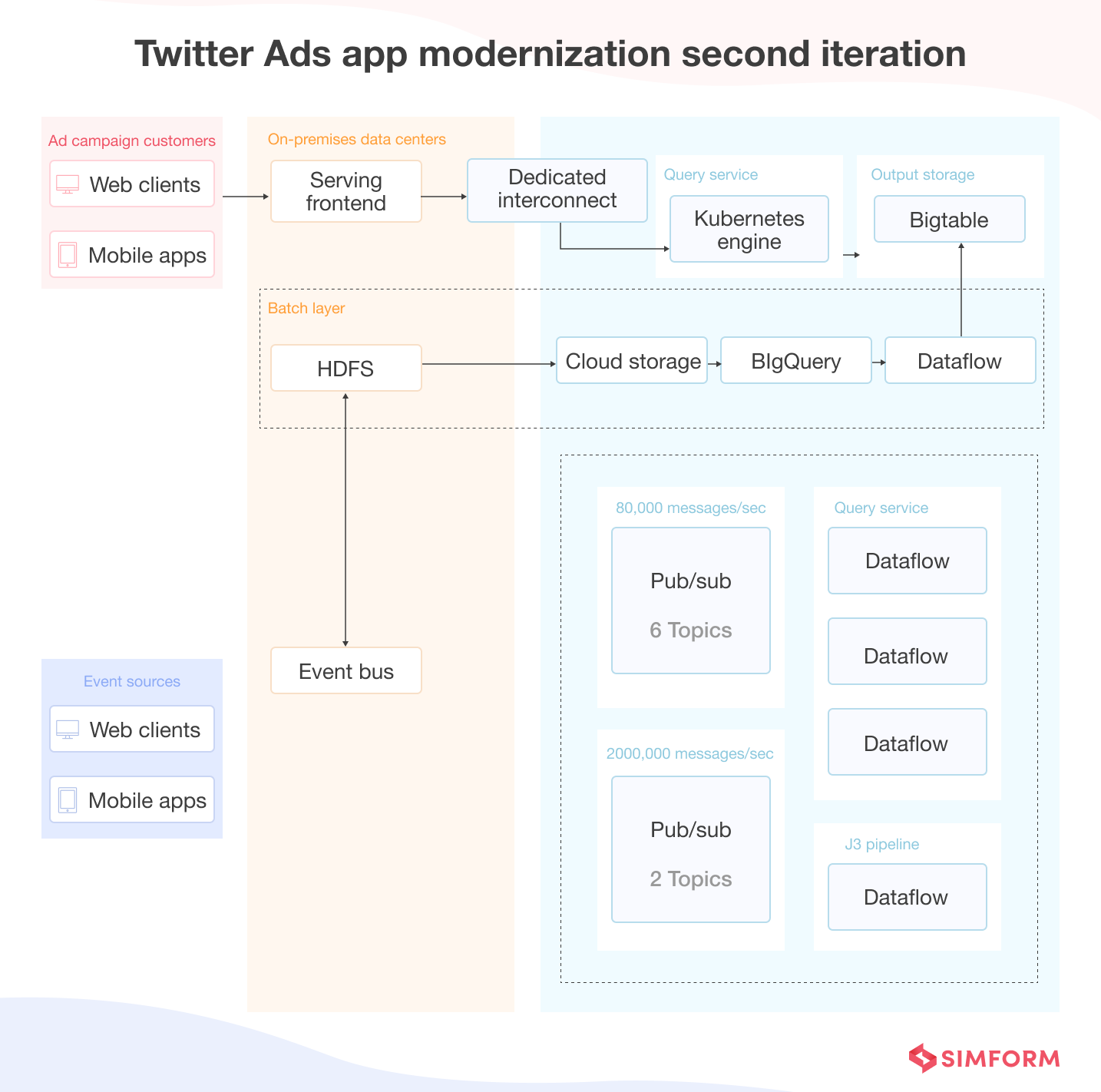
The team chose Apache Beam and paired it with the Dataflow approach to simplify the structure of the Twitter Ads data transformation pipeline. As a result, the platform’s data processing capabilities and reliability also increased significantly.
Further, the team migrated the data from HDFS to cloud storage. Batch Dataflow jobs now load the data on cloud storage regularly. In other words, the entire data streaming has been migrated to the cloud by creating a new layer.
Data ingestion now occurs from the on-premise servers, divided into two streams through Pub/Sub. Twitter Ads has to manage more than 200,000 data ingestions every day. Pub/sub simplifies data streams for ingested information and acts as a messaging-oriented middleware.
How the application modernization strategy of Twitter Ads helped reduce tech debt and improve performance
Re-architecting from a coupled architecture to a decoupled structure helped Twitter Ads to improve release agility within the first six months of transition. Here is how they used the new distributed architecture and a hybrid cloud strategy to overcome tech debt:
- They created a data streaming layer with pub/sub for decoupled streams.
- Using a hybrid strategy, they also migrated parts of the infrastructure to the cloud and kept sensitive data ingestions from on-premise data centers.
Further, the Twitter Ads team used Apache Beam and the Dataworks flow approach to make the real-time data pipeline more reliable and accurate. As a result, developers at Twitter Ads can now configure the existing data pipeline flexibly and build new features faster, without having to worry about tech debt accumulation.
Airbnb’s application modernization with Kubernetes to reduce tech debt
After its launch in 2007, Airbnb had been working on the Ruby on Rails monolith, also called “monorail,” for its platform, supporting more than 5.5 million listings of rental properties across 100,000 cities. As the business grew, tightly coupled monorails had more dependencies, leading to slower releases.
Major challenge: Increased dependencies in the monorail architecture and the need for a continuous delivery cycle
In the initial years, engineers at Airbnb needed to manage 200 commits per day with 15 hours of blockage due to feedback and reverts.
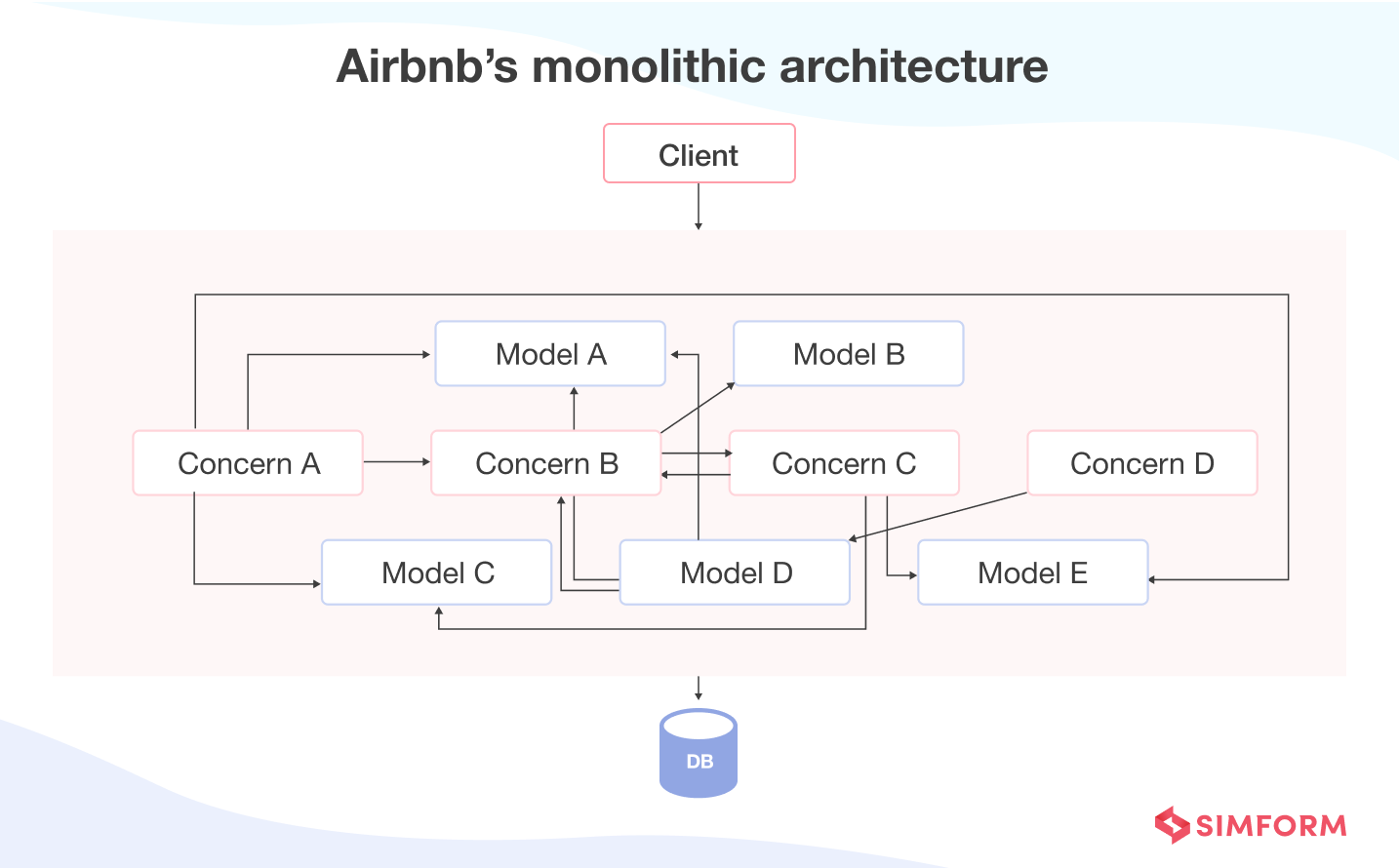
Eventually, the tech debt for Airbnb systems increased with accumulated 220 changes deployed, 30,000 SQL database columns, 155,000 pull requests merged in GitHub, and 1,254 unique contributors daily.
The tightly coupled monorail was causing dependency issues for Airbnb engineers, and in case any problem emerged, rollbacks became more and more time-consuming. So, Airbnb decided to use a service-oriented architecture with Amazon Elastic Compute Cloud (EC2).
Breaking the monolith did help them reduce problems of tightly coupled architecture, but scaling was a significant caveat. Melanie Cebula, Software Engineer at Airbnb, said, “We needed to scale continuous delivery horizontally.”
Each service needed a continuous delivery cycle. So, the team implemented microservices using Kubernetes. They relied on the YAML templates to reduce complexities and abstract away configurations. These templates also allowed Airbnb to migrate legacy services and training engineers easily for the new environment.
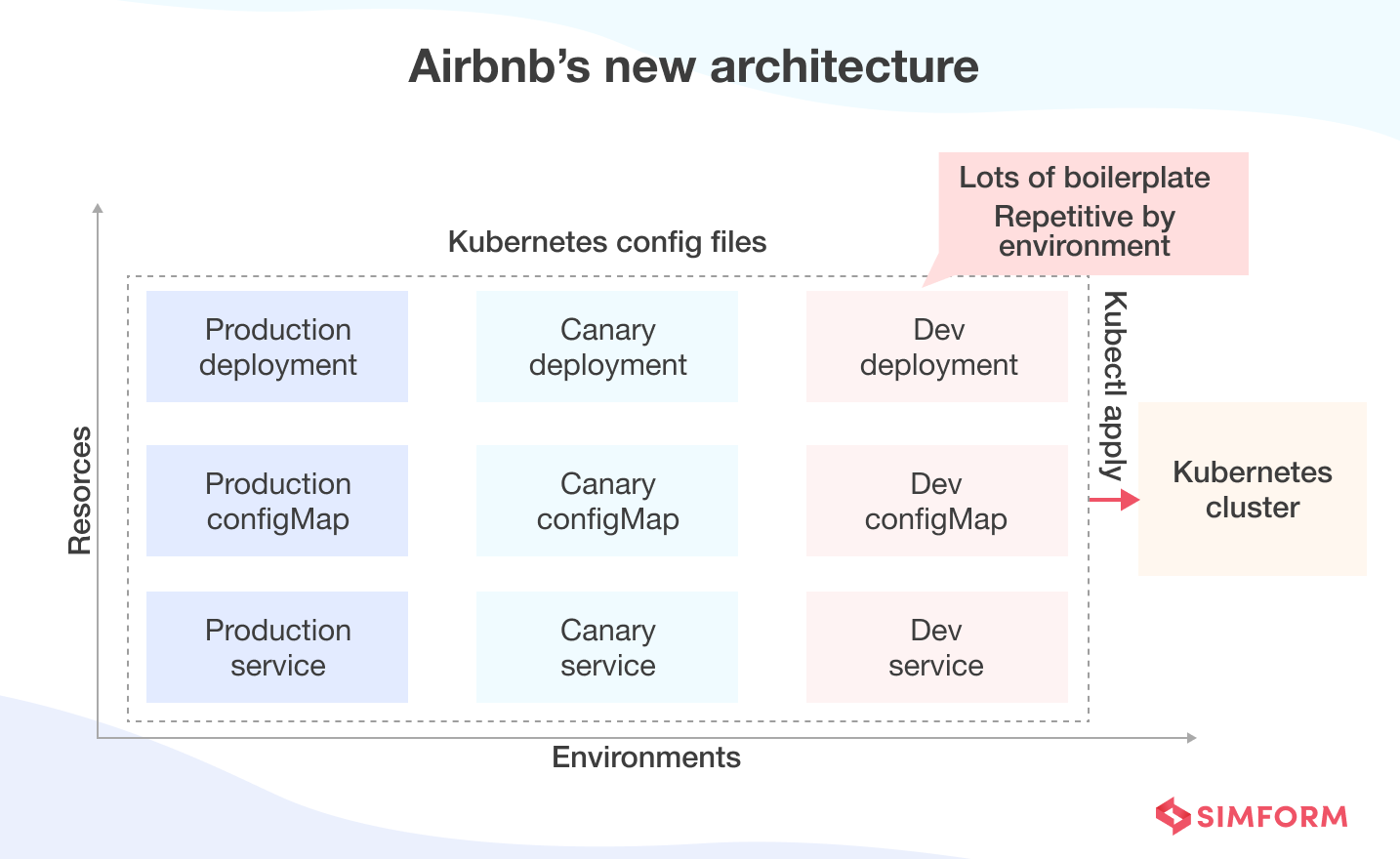
Using the template concept, Airbnb engineers reduced repetition and stored the configuration files in Git. Doing so made reviewing, updating, and committing configuration files more streamlined.
The only major issue that remained was the increasing number of nodes deployed in the production environment.
Solution: Migrating to a multi-cluster Kubernetes environment
In September 2018, Airbnb’s main production cluster reached 450 nodes. By March 2019, Airbnb saw the production cluster increase to 1800 nodes, surging to 2300 in April. At this point, the team figured out that adding more clusters to the environment was more feasible than adding so many nodes in just one cluster.
So they added more clusters and transitioned the system to a multicluster Kubernetes environment using their service mesh, also called SmartStack.
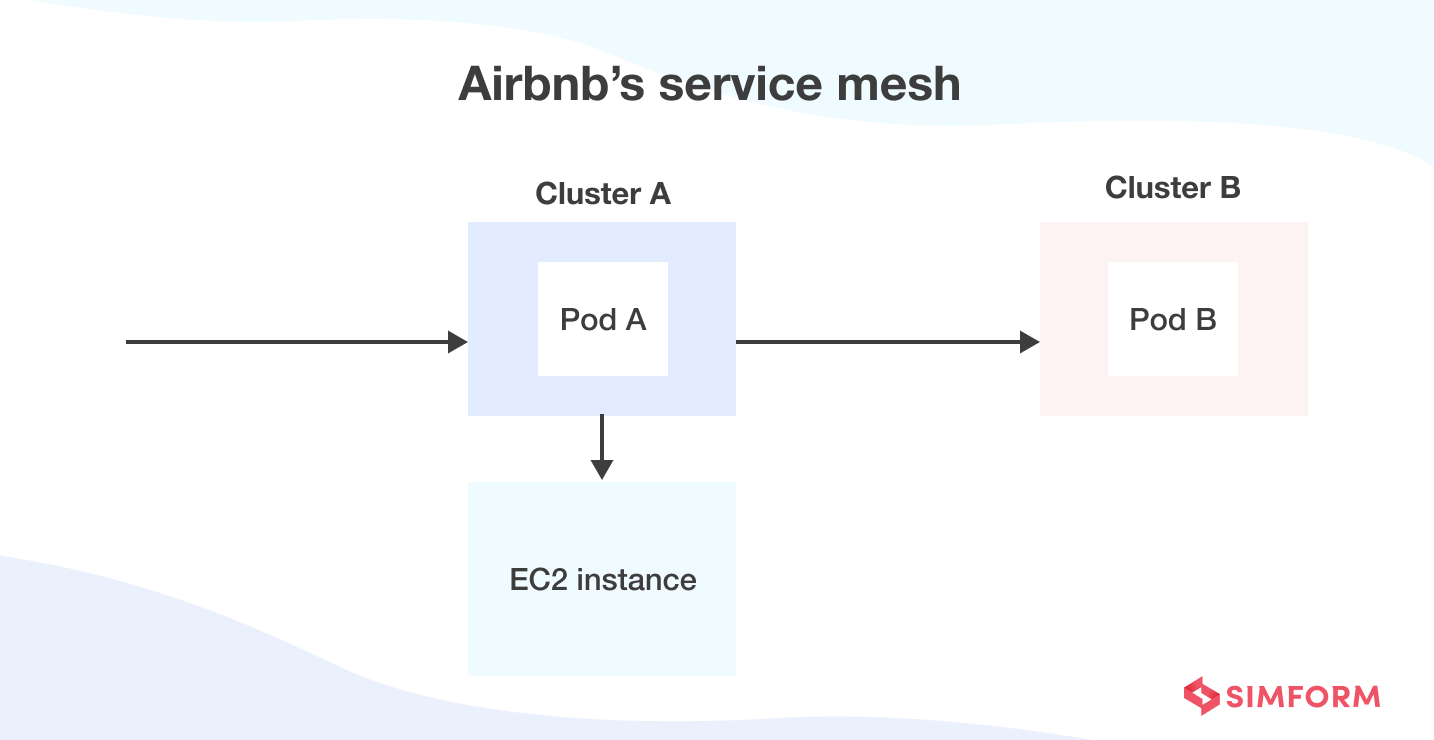
Airbnb’s multi-cluster environment helped assign workloads easily. Workloads are assigned randomly to different clusters, each with a size limit of 400 nodes. However, maintaining consistency in multiple clusters requires a reliable solution. So, Airbnb created in-house Kube systems that helped them deploy clusters.
Kubernetes clusters were first written as Helm charts and templated as a single manifest. Further, engineers at Airbnb began to deploy apps using an internal framework called Kube-gen. Now, it takes them less than 10 minutes to deploy an app with Kube-gen.
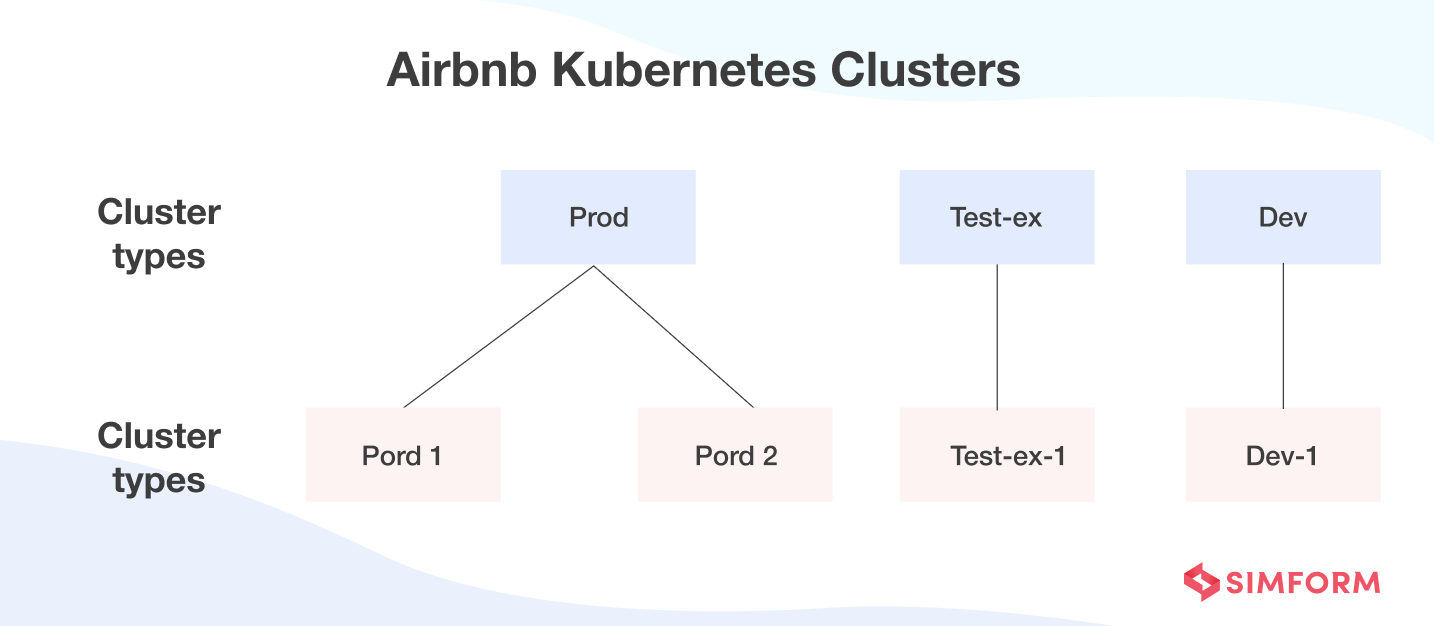
Lastly, Airbnb introduced a type concept where cluster types served as classes and clusters served as instances. This arrangement facilitated the easier organization of all the clusters in the system.
Airbnb improved its release cycles with reduced tech debt
Moving to a decoupled SOA and migrating to Kubernetes helped Airbnb reduce its systems’ tech debt, improve release time, and reduce errors and dependencies. Airbnb also used the multi-cluster approach for Kubernetes, minimizing the number of nodes added for deployments.
In a nutshell, application modernization enabled Airbnb to:
- Reach 125,000 production deploys per year
- Run 50% of services on more than 7000 nodes across 36 Kubernetes clusters
- Add 22 cluster types for production, testing, and deployment
Spotify’s unique application modernization story to deal with tech debt
In its early days, Spotify released a web player and a desktop app to offer music streaming services worldwide. However, Spotify struggled to deliver new features rapidly because of how different the tech stacks of each format were and the complexity arising from context switching.
Additionally, the team faced accessibility issues in both the web player and the desktop app.
So, the engineering team at Spotify tried different approaches to solve these issues while also tackling the tech debt. Ultimately, they decided to modernize their web player, so it matches the feature richness and performance of the desktop app.
Major challenge: Running the same user interface on two different infrastructures
Engineers at Spotify decided to iterate the web player codebase and make it desktop-grade. The web player was developed with the web in mind, had a smaller application size, and was more performant.
On top of that, it worked with various browsers, and its client-side was continuously delivered. For these reasons, the team decided to base the user experience shared between both versions on the foundation of the web player code.
To build a shared UI, the team had to ship and run the web player user interface with the Desktop container. However, they faced several roadblocks while attempting to do so. For example, due to tight coupling with web servers, the web player relied on these servers for all data processing and authentication.
On top of that, the playback system of the web player was not compatible with that of the desktop application. Authentication also worked differently on both platforms. But most importantly, it was difficult to accommodate the advanced features of the desktop app in the web player.
At that point, the team realized they needed to build a system for Spotify that was platform agnostic.
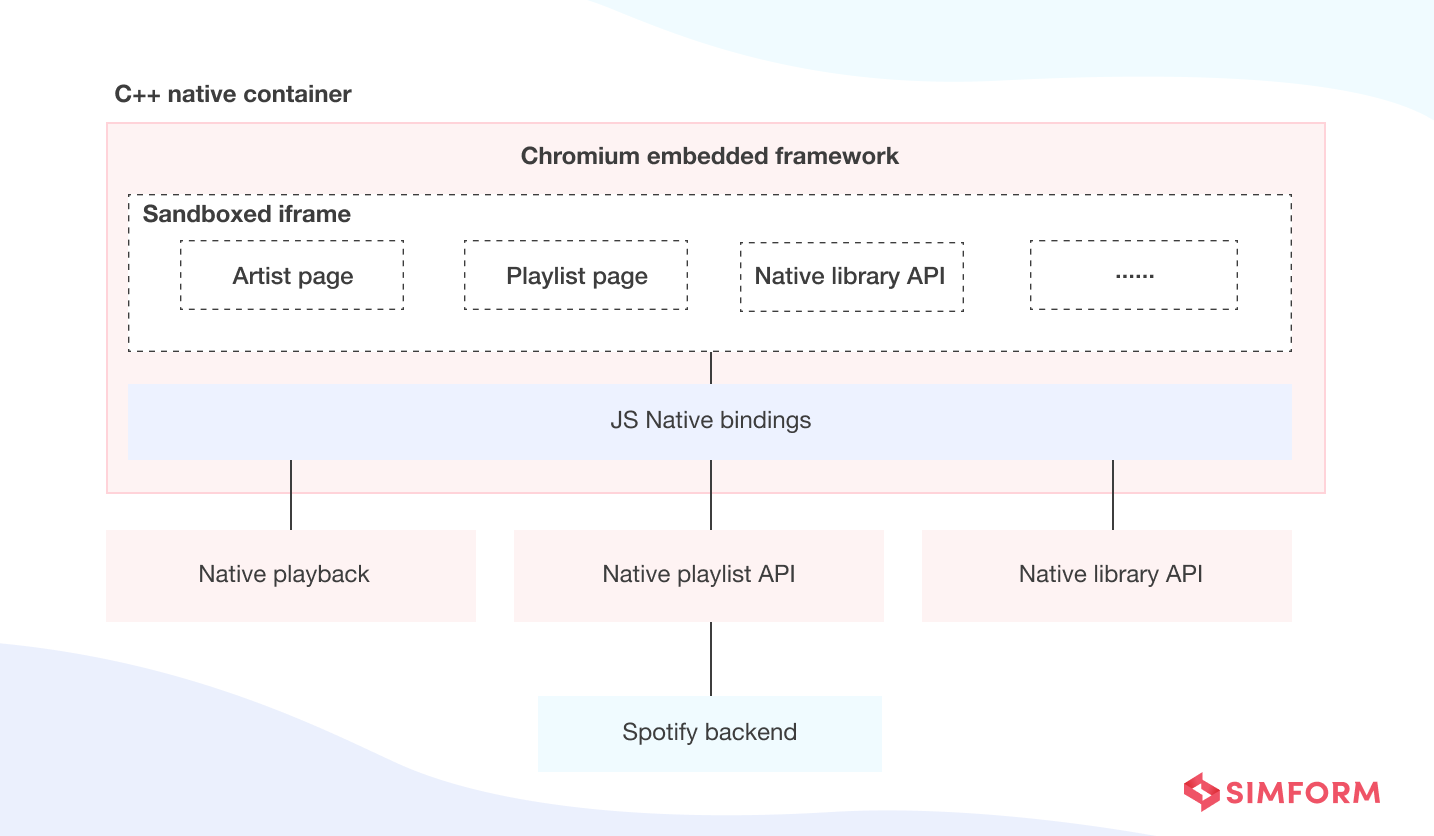
Solution: Re-architecting the frontend and building TypeScript Platform APIs for data sources abstraction
The engineering team at Spotify settled on using React and an API gateway design pattern to re-architect the shared UI. They developed TypeScript Platform APIs to abstract data sources and playback stacks to keep the UI platform agnostic. They also rewrote the whole UI in TypeScript to revolutionize the whole Spotify user experience bit by bit.
The final architecture looked like a layer of Platform APIs that exposed the underlying Spotify ecosystem to a React-based user interface. Further, the Platform APIs were exposed via React Hooks. The new interface is now platform agnostic and works fine regardless of whether the data comes from the web server or C++ stack.
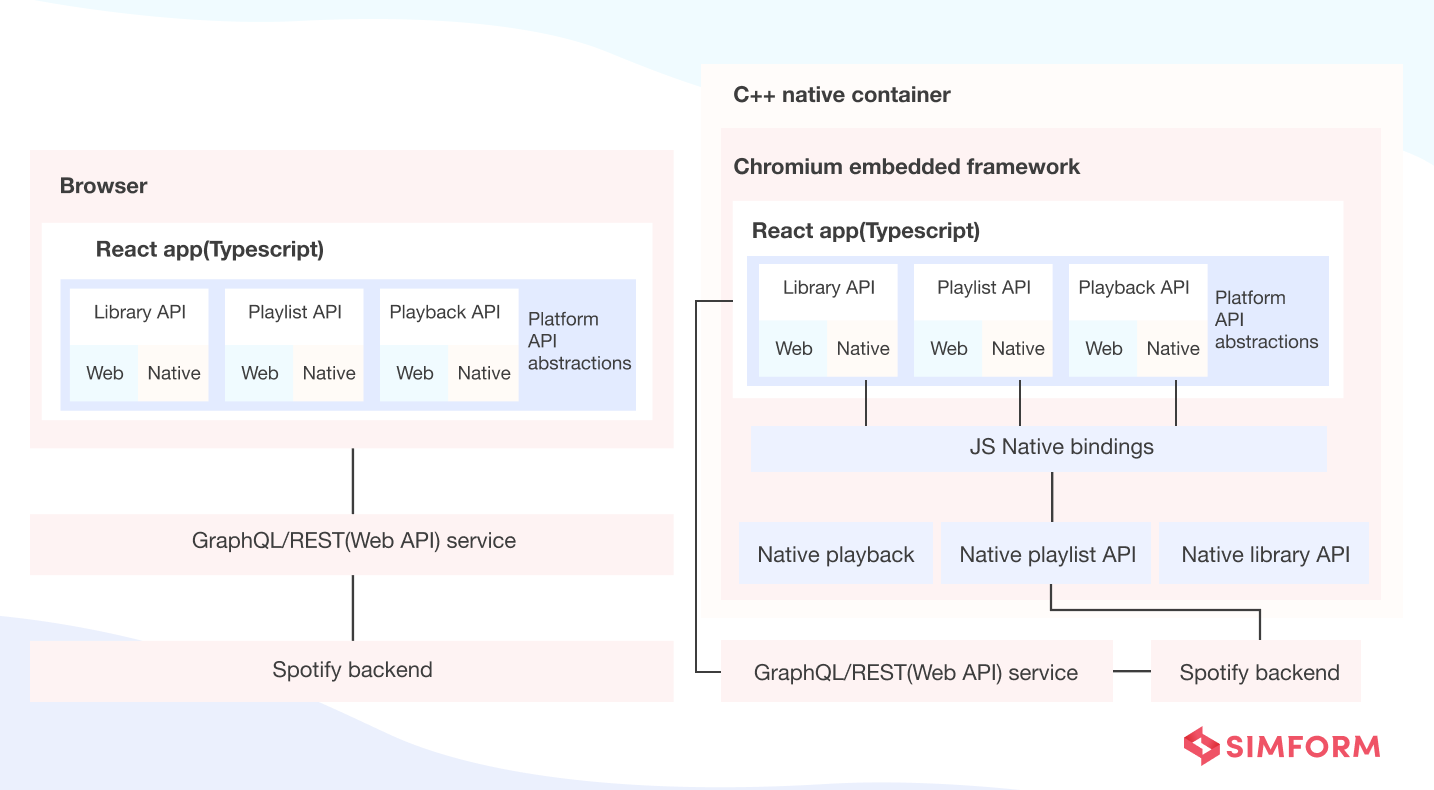
Re-architecting the UI equipped Spotify to offer a consistent multi-channel experience
Spotify wanted to use the desktop app’s features in the web player UI without compromising performance. However, redundancies and tech debt of tightly coupled web player components were major challenges. So, they re-architected the frontend infrastructure to an API-based design pattern to achieve the following:
Increased velocity for the development teams
Added features to the web player like downloading, offline mode, local files, lyrics, a “Now Playing” queue, sorting and filtering of playlists and albums
Complete launch of the new desktop client with advanced features within a year
Lyft’s migration to Kubernetes to reduce infrastructure debt
Lyft is the second largest ride-sharing service provider. However, soon after it became successful, scaling the services across several cities in the US and Canada required rebuilding the infrastructure to facilitate efficient scaling.
Major Challenge: Tech debt and dependencies between the infrastructure and the application layers
Lyft’s legacy infrastructure outgrew its capacity a few years after its launch.
According to Viki Cheung, Engineering manager at Lyft, “Like a typical startup story, Lyft was scrappy in the beginning and just built whatever was needed to ship the product. It just organically grew from there. There was never a time to overhaul the systems.”
Moreover, the old architecture was a hybrid structure with SOA and monolith. In addition to maintaining the application code, developers also had to spend considerable time maintaining the infrastructure code. The company wanted to separate both layers so it could free developers from working on the infrastructure code.
Solution: Migrating to Kubernetes and creating a hybrid environment for communication with legacy services
To address the above challenges, Lyft began to migrate to Kubernetes in 2018.
Before the migration, Lyft’s engineering team worked with virtual machines on AWS. They had created Envoy, a distributed proxy for applications and services, to manage the system’s network. It has a communication bus and a universal data plane for large microservice “service mesh” architectures.
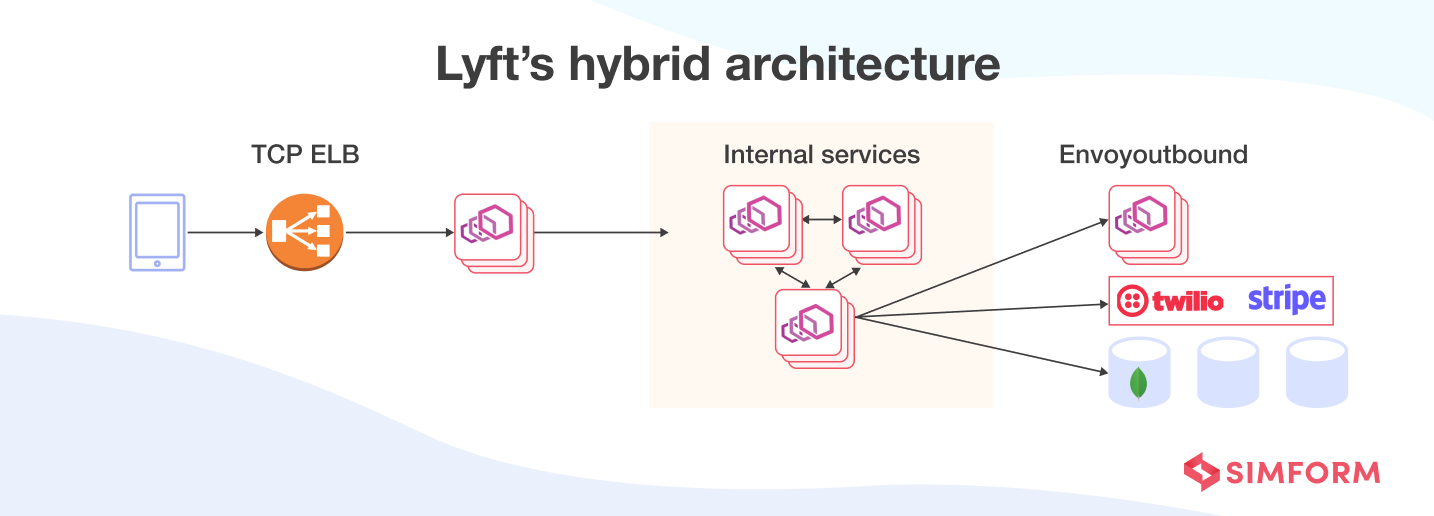
Lyft had two important goals for migration to Kubernetes,
- Transparency for product engineers
- Higher reliability, incremental rollouts, and easier rollbacks.
Envoy played a crucial role in Lyft’s migration by creating an abstraction layer that routed the data to services making requests.
Envoy is based on the sidecar design pattern and runs parallel to every app abstracting the network. It provides common features for platform-agnostic applications. Visualization of problem areas, fine-tuning the performance, and adding new features becomes easy when all the service traffic flows through Envoy mesh.
Envoy xDS (discovery services and APIs) control plane pulls data from legacy services and uses Kubernetes watch API to fetch the IP addresses of pods. Further, all the data is configured into Envoy sidecars creating a hybrid environment for Kubernetes to communicate with legacy services.
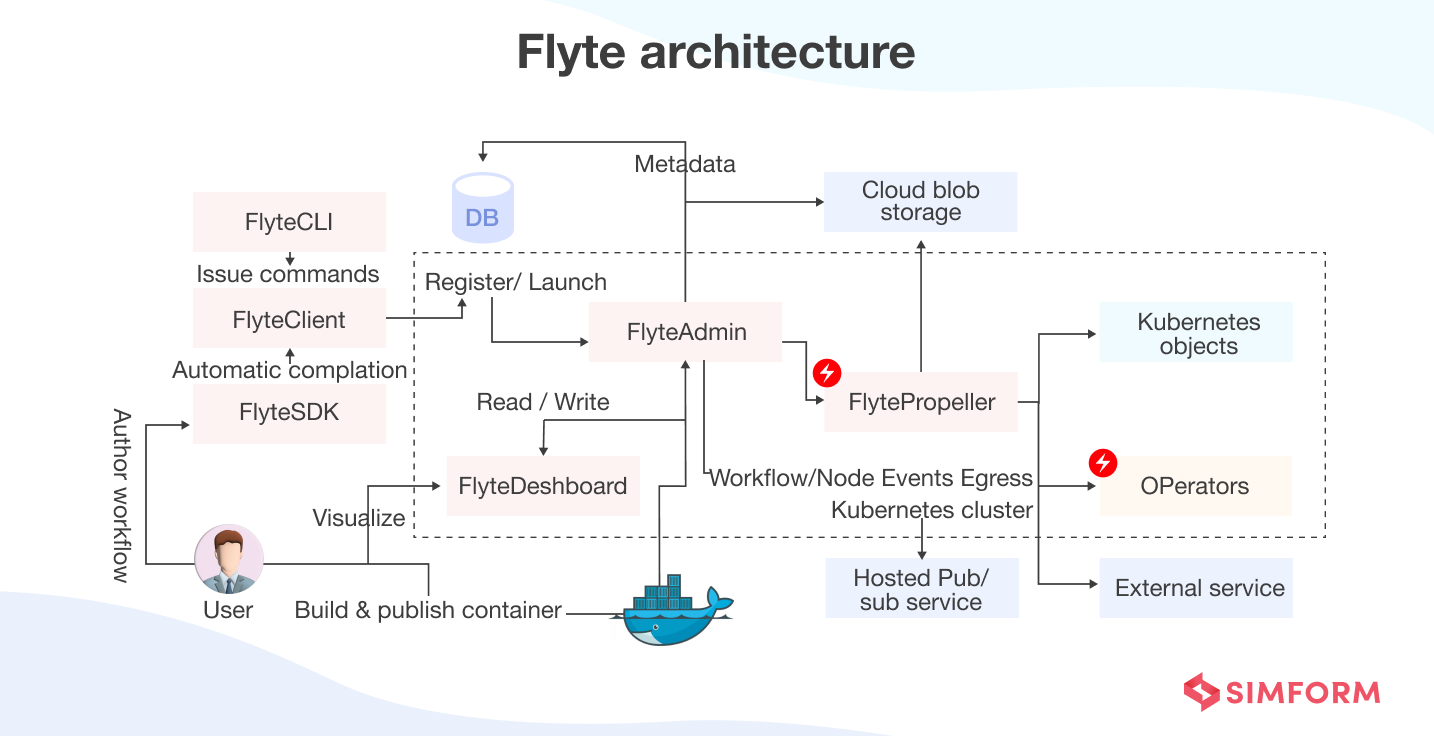
From 2018 to 2020, Lyft migrated machine learning workloads and stateful and stateless services to Kubernetes using the side card design pattern. Moreover, Lyft also created a distributed processing platform known as Flyte. It runs machine learning workloads and data workflows on 10,000 pods cluster.
Lyft reduced tech debt and increased observability through application modernization
Lyft’s application modernization and migration to Kubernetes reduced the tech debt of tightly coupled architecture. It also helped Lyft achieve better visibility for engineers. Using Flyte and Envoy, Lyft has deployed the following:
- 600 microservices running on 300,000 containers on a single Envoy mesh
- A ride-sharing cluster made of 30,000 pods that scale automatically
- Fault-tolerant EnvoyManager to operate and optimize the system’s multi-cluster environment
NBA reduced tech debt and revamped the fan experience through application modernization
NBA is a fan-driven organization delivering a unique experience for basketball lovers. So, keeping up with the fans’ demands and technology needs has always been crucial for NBA.
The IT Application Development Group of the NBA was dedicated to delivering an elegant user experience for fans. However, there were still some challenges of scaling, real-time delivery, and technical debt.
Major challenge: Slower time to market due to huge technical debt
NBA serves unique fan experiences for more than 400 million fans worldwide. However, technical debt and outdated systems made the new releases slower. So, they considered application modernization to improve the time to market.
Another major challenge that NBA faced was creating enterprise mobility solutions for 1800 employees using 50+ applications.
Solution: Partnering with Microsoft Azure for application modernization
Improving fan experiences requires enhanced analytics. NBA sourced data from multiple resources across virtual private cloud, hybrid, and on-premise environments.
However, the tech debt of the old infrastructure and managing data access was a massive challenge. So they partnered with Microsoft Azure for application modernization.
NBA simulated the fan experience of being physically present in an arena. Especially during the pandemic, when physical access to stadiums was not feasible, NBA offered virtual simulations using Microsoft Azure services.
NBA also launched REPS (Referee Engagement and Performance System), which helped improve the referees’ game experience. It uses a centralized performance platform with video integration and social messaging features. So, referees can watch, analyze, share, save, and comment on the plays.
Moreover, NBA built an enterprise mobility platform called NBAOne. It is a mobile-first application that enables employees to use multiple applications through a single sign-in.
How reduced tech debt helped NBA revolutionize the fan experience
Virtual simulation of the fan experiences required high-performance computations, which were not possible with the technical debt of legacy systems. So, NBA modernized its applications and infrastructure with Microsoft Azure to improve
- Automation of critical tasks like scaling, repo management, and security
- App recommendations for users and employees
- Time-to-market for new feature releases
Natura’s GSP and its performance optimization with application modernization
Natura launched the Global Sales Platform (GSP) for the company’s beauty sales consultants. GSP helped Natura embed key aspects like Registration, Management of the Business Model, and Relationship of the Direct Sale.
However, the challenge was creating a high-performance platform that could cater to customers’ needs across the globe.
Major challenge: Optimizing the performance of GSP after it was re-architected as microservices
Natura was new to an event-driven microservices architecture. After re-architecting the old system to a microservice architecture and deploying it for the first time, Natura’s team faced the challenges of high functional range, integration between components from different platforms, deployment of non-functional components, and operational aspects.
Soon after the first deployment, the Natura family expanded to include several other brand experiences on its GSP. As a result, all the challenges that the team faced after the first deployment became even bigger and more complex.
At that point, Natura realized they needed guidance from the right experts to streamline their platform’s performance. So Natura reached out to AWS professionals to help them optimize the general performance of GSP.
Solution: Reviewing and fixing GSP’s architecture with WAFR
The Natura engineering team and AWS professionals formed a team of 15 members that assessed the infrastructure, architecture, system requirements, performance, etc.
The assessment took place within eight weeks, and recommendations were generated and prioritized to ensure GSP platform deployment was in accordance with WAFR guidelines.
The AWS Professional Services team acted as orchestrators and helped Natura’s technical team with key deployment modules.
WAFR enabled Natura to achieve operational excellence
Natura implemented WAFR recommendations, and the results have been outstanding. GSP is now optimized for performance and is free from integration issues. The team can make upgrades to the platform easily, without having to worry about technical debt accumulation.
Additionally, the Natura engineering team also faces fewer operational challenges and has gained significant results, including
- Improvement of APDEX (Application Performance Index) from 0.78 to 0.96
- Increased performance without functional loss
- Higher resilience of the system and fault tolerance
How Simform helps reduce tech debt through application modernization
Organizations marching towards digital transformation often have to deal with considerable tech debt, including legacy software stacks, old architectures, outdated approaches, and more.
Working with the system to modernize it and reduce its tech debt requires top-notch expertise in digital product engineering. And that’s what we at Simform excel in.
Some time back, a leading manufacturing company approached us for enterprise solutions with application modernization as their main focus. The stakeholders (rightly) had concerns like data security, increasing dependencies between application components, TCO, the scope of ROI, and more.
Upon detailed project discussions with our tech consultants, the client decided to partner with us to modernize their legacy RFQ system and migrate it to the cloud infrastructure.
Tech consultants at Simform helped them build a modernization roadmap, and upon its execution, the client was able to reduce the turnaround time for generating quotes by over 70%.
We take pride in delivering complex engineering solutions that enable our clients to make their business processes more efficient, faster, and more cost-effective. If you are a business that is aiming to modernize its legacy systems in the most optimum way, we would love to have a chat with you!
Just drop us a message here with your requirements, and our consultants will get in touch with you to discuss your project in detail.