Companies cannot afford application downtime today. Even brief outages have had a severe impact on revenue, customer confidence, and brand reputation for companies of all scales. However, building and running resilient applications that provide always-available experiences has historically been complex.
AWS has made significant investments in building the world’s most resilient cloud. With a comprehensive suite of purpose-built resilience services, architectural guidance, and best practices, AWS empowers organizations to build and operate applications that can rapidly recover from disruptions.
In this blog post, we will explore what attributes make applications resilient and how to architect them using AWS services.
To start, let’s define the key pillars of application resilience.
Understanding resilience in applications
Application resilience is the ability of an application to continue functioning and meet its service-level objectives despite failures, anomalies, traffic spikes, or other stressful conditions that may occur. A resilient application accepts the fact that failures will happen. Instead of trying to achieve 100% reliability, it focuses more on failure recovery capabilities.
In essence, resilient applications are designed and architected to provide high availability, measured by the percentage of time an application is functioning for users. They also incorporate disaster recovery capabilities that allow the application to be restored and resumed quickly in case of rare large-scale failures or disruptions to the operating environment. The common characteristics and traits of a resilient application are as follows:
- High availability: The application ensures maximum uptime and availability despite failures or spikes in traffic. It achieves this through horizontal scaling, geographic distribution, and auto-recovery capabilities.
- Fault tolerance: The application is designed to continue functioning properly even when certain components fail or introduce errors. This is typically done through the redundancy of critical components.
- Performance under stress: The application maintains adequate performance metrics like response time, throughput, and latency even when subjected to an unusually high load. Stress testing helps benchmark and improve performance.
- Quick recovery: The application has remarkably quick recovery times in the cases of a failure, be it through automatic remediation or manual intervention with preset recovery protocols.
- Monitoring: The application has enough observability through metrics, logging, and tracing to detect anomalies and issues in real-time. Proactive alerts are set up for rapid incident response.
- Graceful degradation: When excessive loads trigger performance issues, the application does not fail completely but rather sacrifices lower priority capabilities to maintain core functionality.
- Designed for change: The application is built using agile methodologies and modular components that can adapt quickly to changing business needs and scale demands.
Understanding resilience characteristics is the first step – implementing them relies on cloud platforms like AWS with an integrated suite of availability tools and robust infrastructure. In this blog post, we will outline the steps involved in building resilient applications with AWS specifically.
Strategies for building resilient and highly available applications with AWS
AWS enables cloud architects to fundamentally design availability, recoverability, observability, and stability into applications leveraging fail-safe infrastructure. Let’s understand the step-by-step approach to building and monitoring applications for resilience with AWS.
1) Establish a solid foundation with a strong underlying infrastructure
A well-defined underlying infrastructure acts as the backbone of your application and makes it scalable. Infrastructure that sports multiple measures, such as autoscaling, will lead to better odds of adapting to dynamic demand cycles. Your infrastructure’s fault tolerance mechanisms also dictate how resilient your application is to the corruption of one or more components and the time that it takes to recover from the issues through remediation procedures. You can strengthen your infrastructure by implementing the following practices:
Automate the infrastructure provisioning process
Automating infrastructure provisioning through scripted templates and programmatic interfaces replaces manual processes prone to human errors and delays. Standardization and self-service capabilities empower developers to consistently integrate resiliency patterns like redundancy and decoupled services by enabling faster, low-risk infrastructure iterations.
- AWS CloudFormation
 AWS CloudFormation is an infrastructure-as-code service that allows codifying infrastructure in reusable templates. By defining infrastructure resources like servers and databases in easy-to-read YAML/JSON templates, CloudFormation automates provisioning with version control and validation.
AWS CloudFormation is an infrastructure-as-code service that allows codifying infrastructure in reusable templates. By defining infrastructure resources like servers and databases in easy-to-read YAML/JSON templates, CloudFormation automates provisioning with version control and validation.
Use autoscaling
The overutilization of any single computing resource leads your application to become strained, and if the resources fall short, it may lead to performance degradation or a complete disruption of services. This is why you need resources that can autonomously scale up and down according to the user’s requirements.
- Amazon EC2 Auto Scaling
AWS services such as Amazon EC2 Auto Scaling not only increase the number of compute units based on demand but also constantly monitor all running instances with its health checks. Once an impaired or terminated instance is detected, it automatically replaces said instance to ensure that only the right number of running instances and maintain redundancy.
Embrace concepts like CI/CD
Implementing development practices such as CI/CD promotes the development of high-quality code and teamwork through automation and standardized testing. Overall, embracing CI/CD leads to quick updates and fixes without compromising on quality standards. The following solutions from AWS help you build a highly scalable CI/CD pipeline:
- AWS CodeBuild
AWS CodeBuild automates the process of compiling source code alongside the process of testing and making them into readily deployable artifacts. It is also not limited to a single programming language or framework, allowing you to use it for multiple build scenarios.
- AWS CodePipeline
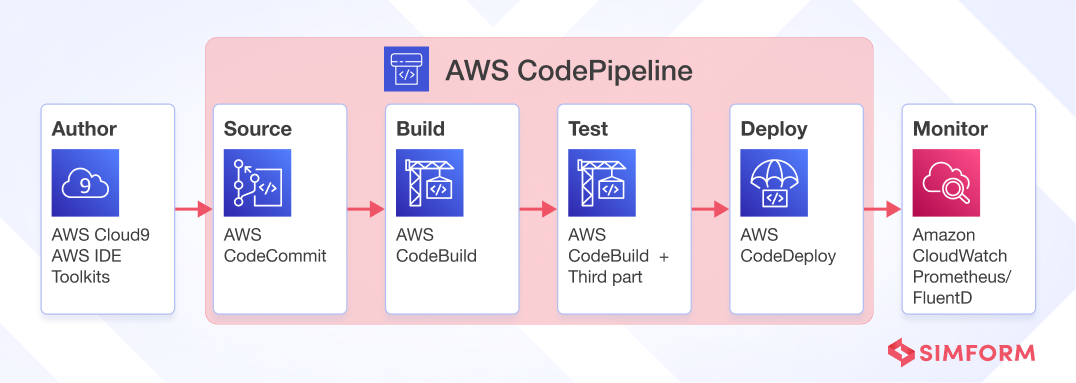
As the name suggests, AWS CodePipline is used to create a pipeline of multiple stages to automate the software development and delivery process. It is an event-driven service that initiates different stages of development, such as building, testing, and deployment, based on fixed triggers after manual authorization to make development fast and secure.
- AWS CodeDeploy
AWS CodeDeploy automates the deployment process across multiple environments, such as development, test, and production environments. The deployments performed by AWS CodeDeploy ensure high availability by using rolling updates and blue/green deployments. You also get automatic rollbacks to revert to the previous functioning app version in case of a failure to keep your application resilient against failures caused by the deployment of updates.
Since all of these services readily integrate with each other, they allow you to easily implement a well-functioning CI/CD pipeline to enhance the delivery speed and resilience of your application.
Leverage immutable infrastructure
Being able to constantly update infrastructure to adapt to changes, is a characteristic of mutable infrastructure. While this does sound good initially, the constant changes made to the components raise the chances for inconsistencies within the infrastructure’s configuration, which consequently increases the likelihood of failures occurring.
Immutable infrastructure eliminates the chances of configurational drift as it does not allow for the modification of resources upon deployment. Instead of changing the component during an update, immutable components are simply replaced to simplify deployment and keep the infrastructure performing consistently.
Services from AWS Amazon Machine Images (AMIs) and AWS CodeDeploy, come together to make your infrastructure immutable by automatically building and deploying the necessary artifacts while maintaining a consistent version history.
- Amazon Machine Images (AMIs)
Amazon Machine Images (AMIs) are pre-configured, hardened virtual machine images that underpin the EC2 compute instances spun up in AWS. Using AMIs enables an immutable server infrastructure pattern – rather than updating live servers, new instances are deployed from consistent AMIs. This reduces configuration drift and unknown changes that lead to downtime when nodes fail. Instantly recreating pristine EC2 instances from known AMI snapshots provides resilience through predictable, interchangeable infrastructure.
- AWS CodeDeploy
AWS CodeDeploy automates code deployment to EC2 instances. By integrating CodeDeploy with immutable AMIs, new containers or software versions roll out by launching instances from fresh AMIs rather than updating existing servers. This application deployment automation eliminates manual errors, ensures standard environments, and allows fast rolls back, enabling consistent, resilient software delivery under immutable infrastructure models.
Since these services integrate with each other, you can create an automated pipeline for building, testing, and deploying applications, which is a key aspect of managing immutable infrastructure.
2) Design for high availability
Designing for high availability (HA) means architecting infrastructure and applications to provide the maximum possible uptime and minimize service disruptions from the start. Rather than considering availability as an afterthought, it is baked into design principles across technology, process, and people dimensions. Below are the sub-steps to design your application for high availability:
Physically distribute resources and components
Having resources spread across multiple Availability Zones enhances application resilience. If one zone faces service issues, traffic can reroute to maintain performance. This prevents regional outages from crashing the entire application.
Various services from AWS can be deployed to the physical availability zone of your choosing to help you improve the performance and resilience of your application for the concerned availability zone. The services that can be deployed in multiple availability zones include Amazon EC2, Amazon S3, Amazon RDS, and more.
- Amazon EC2
Compute instances from Amazon EC2 can be deployed to multiple locations across the world through existing availability zones to increase performance and redundancy. You can have AWS choose the best availability zones for you or choose them yourself according to your requirements. Amazon EC2 also supports placement groups, allowing you to control how instances are placed within the infrastructure to reduce latency and increase throughput.
- Amazon S3
Amazon S3 provides highly durable and available cloud object storage. S3 redundantly stores objects across multiple facilities and servers within a region. This distributed model withstands failures and replicates objects for low-latency access, delivering resilience through the geographic distribution of component resources and data.
- Amazon RDS Multi-AZ
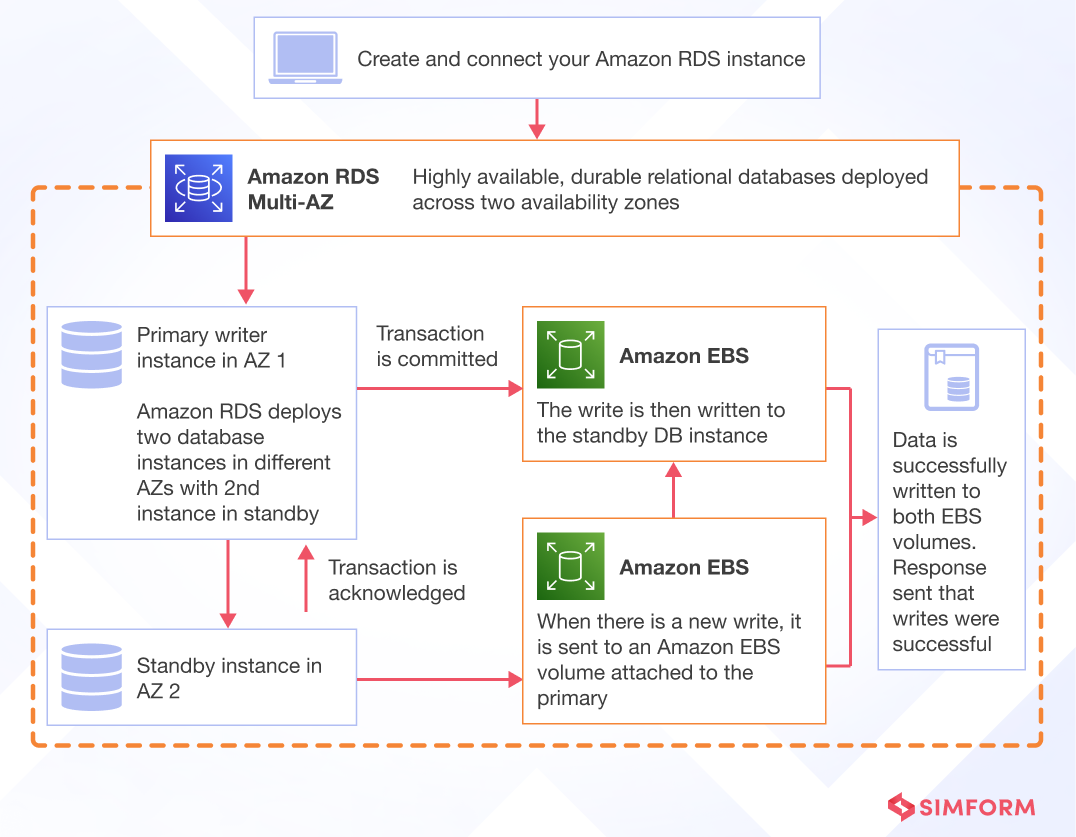 Amazon RDS manages high-availability database instances and replication. RDS databases automatically create resilient mirror replicas across isolated availability zones. This database distribution and failover modeling provides redundancy, smoothing performance during disruptions and outages through zone-resilient architectures.
Amazon RDS manages high-availability database instances and replication. RDS databases automatically create resilient mirror replicas across isolated availability zones. This database distribution and failover modeling provides redundancy, smoothing performance during disruptions and outages through zone-resilient architectures.
Duplicate components of your app
Deploying duplicate critical components across multiple isolated locations or clusters improves availability by eliminating individual points of failure. For example, horizontally scaling app servers across zones ensures one failing server does not disrupt operations. Though initially more resource intensive, duplicating stateless application building blocks and keeping redundant persistence layers in sync facilitates resilient, always-on applications with nano-second failovers transparent to users.
- Amazon Auto Scaling Groups
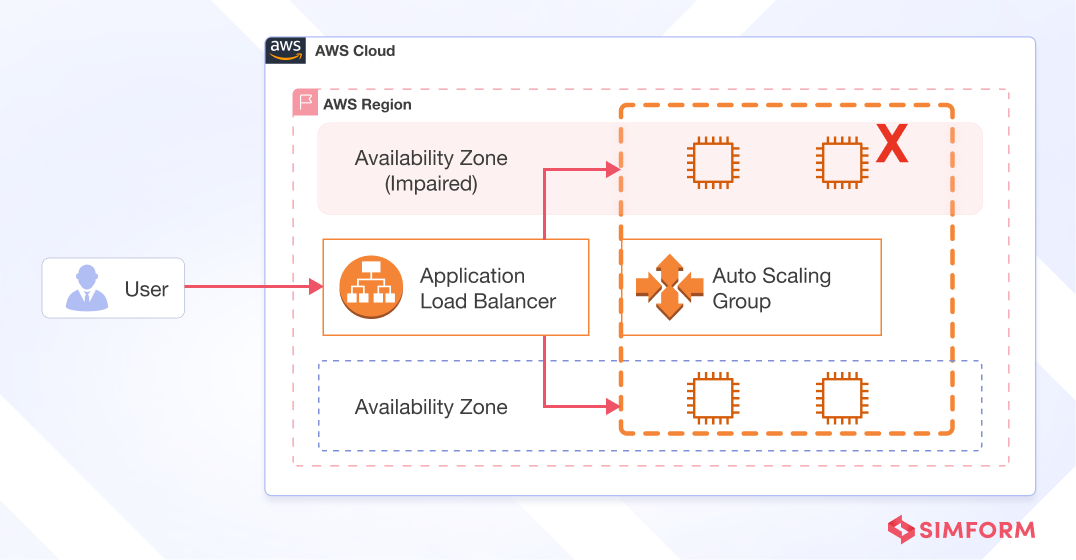 Amazon Auto Scaling Groups allow defining templates and rules to automatically launch additional compute instances in response to high demand. Auto Scaling Groups also replace any failed instances with resilient parallel capacity, enabling elastic duplicates for both redundancy and scale.
Amazon Auto Scaling Groups allow defining templates and rules to automatically launch additional compute instances in response to high demand. Auto Scaling Groups also replace any failed instances with resilient parallel capacity, enabling elastic duplicates for both redundancy and scale.
- Amazon Aurora
Amazon Aurora is a managed relational database service that duplicates data across multiple Availability Zones through high-speed replication protocols. By continuously backing up data to resilient storage nodes across geographic locations, Aurora minimizes disruption and maintains availability even during outages and component failures.
Use load balancers
Spreading the traffic across multiple systems is an integral part of ensuring that your application is not phased by excessive load on specific servers. This is why load balancers are used to prevent resources from being overly strained and to maintain a steady performance output for the application.
- AWS Elastic Load Balancing
With AWS Elastic Load Balancing (ELB), you can take this a step further, as it allows for automatic load balancing across multiple availability zones and targets to ensure consistent availability of the application to the end user.
- Amazon Application Load Balancers
Amazon Application Load Balancers route traffic to multiple services based on the content of the request rather than just network parameters. This content-based routing allows finer control over distributing load which improves performance.
AWS Global Accelerator
Amazon Global Accelerator directs traffic to applications through Amazon’s worldwide network of edge locations for the lowest latency. It continuously monitors health checks and automatically shifts traffic from one Application Load Balancer to another if there are performance issues or failures. This improves availability while allowing customers to implement resilience patterns around active-active or active-standby across regions.
Containerize your app
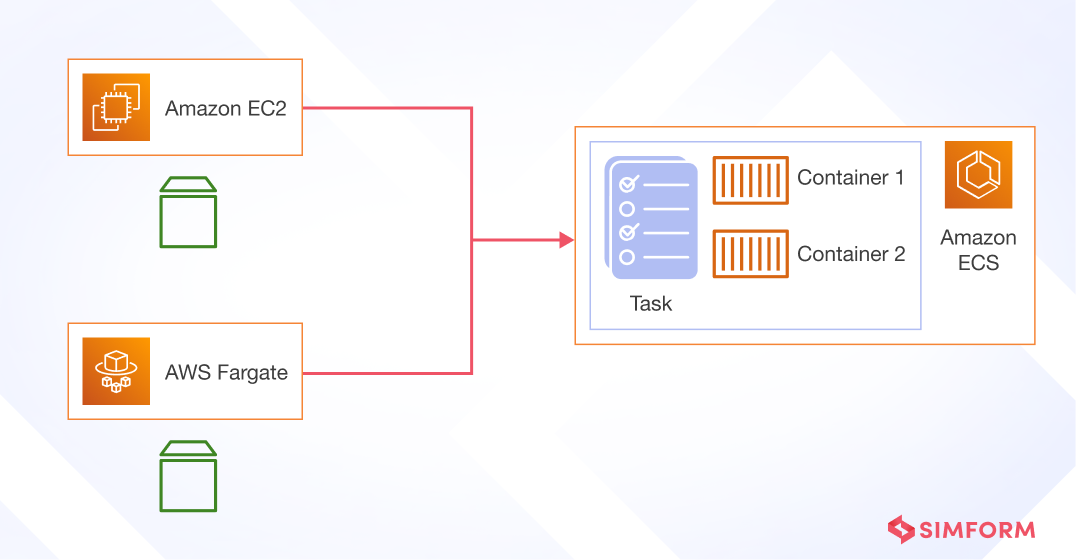 Containers facilitate replicating and distributing copies of services across zones to protect from failures. Their lightweight nature also enables rapid launches, fast failovers, and autoscaling capabilities critical for resilience. Decoupled architectures allow parts of applications to adapt without impacting other components. By compartmentalizing into separate containers connected through APIs, you can limit the blast radius from issues and outages.
Containers facilitate replicating and distributing copies of services across zones to protect from failures. Their lightweight nature also enables rapid launches, fast failovers, and autoscaling capabilities critical for resilience. Decoupled architectures allow parts of applications to adapt without impacting other components. By compartmentalizing into separate containers connected through APIs, you can limit the blast radius from issues and outages.
- Amazon ECS or EKS
Using Amazon Elastic Container Service (ECS) or Amazon Elastic Kubernetes Services (EKS), you can easily deploy, manage, and scale all of your containerized applications, which takes out much of the stress of managing a containerized application.
- AWS Fargate
Additionally, you can use AWS Fargate to completely do away with the worries of managing infrastructure for your containers as it configures servers and clusters dynamically to meet the requirements of the containerized application without any human intervention.
- Amazon ECR
Amazon Elastic Container Registry (ECR) allows users to manage and deploy Docker container images securely. Not only can you instantly store and maintain a version history of your container images, but you can also limit the access that users have to the container images to keep them consistent and secure. Because Amazon ECR can readily integrate with other services, such as AWS Fargate and Amazon EKS, the deployment of the containerized applications becomes rapid across multiple regions.
Test your app
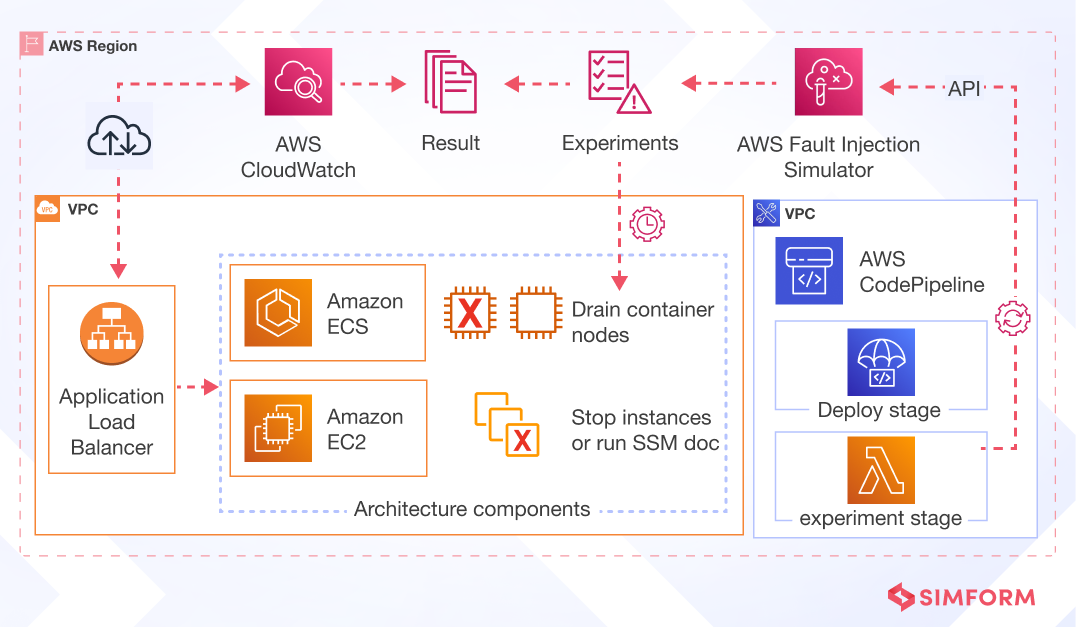 Purposefully testing the applications by inducing failure conditions is important to ensure that all the metrics and responses to failures function as intended in the case of a system anomaly. Not only does testing validate the measures put in place for resiliency, but it also allows you to implement additional measures for fostering continuous improvement and prepare preset protocols for recovery.
Purposefully testing the applications by inducing failure conditions is important to ensure that all the metrics and responses to failures function as intended in the case of a system anomaly. Not only does testing validate the measures put in place for resiliency, but it also allows you to implement additional measures for fostering continuous improvement and prepare preset protocols for recovery.
- AWS Fault Injection Simulator
You can use the AWS Fault Injection Simulator (FIS) to conduct chaos testing and stress tests on your infrastructure to see how it reacts to pre-built simulated scenarios where the application is under load. Furthermore, the AWS Fault Injection Simulator can be integrated with your existing delivery pipeline to repeatedly test the application before deployment.
- AWS X-Ray
You can use AWS X-Ray to figure out the dependencies of your application and how components interact with each other. AWS X-Ray is used for tracing and analyzing requests, which can be used to inject faults into specific components to see how resilient the application is. It can also track the error rates to help you detect anomalies early.
3) Enable continuous monitoring
Continuously monitoring your application is a surefire way to detect the early warning signs of system vulnerabilities and bottlenecks. The earlier you catch these signs, the better your chances are at resolving them beforehand to avoid a system failure. Upon monitoring your application, you may also find trends and patterns that help you understand how to scale your application effectively ahead of time. Let us see how continuous monitoring can be implemented for better resiliency.
Track application logs
Application logs are generated by software solutions that contain detailed information on all the interactions and updates that have been made to the app. These logs boost resilience by facilitating the early detection of underlying issues and the root cause of errors by presenting the entire timeline of changes made to the application.
- AWS CloudTrail
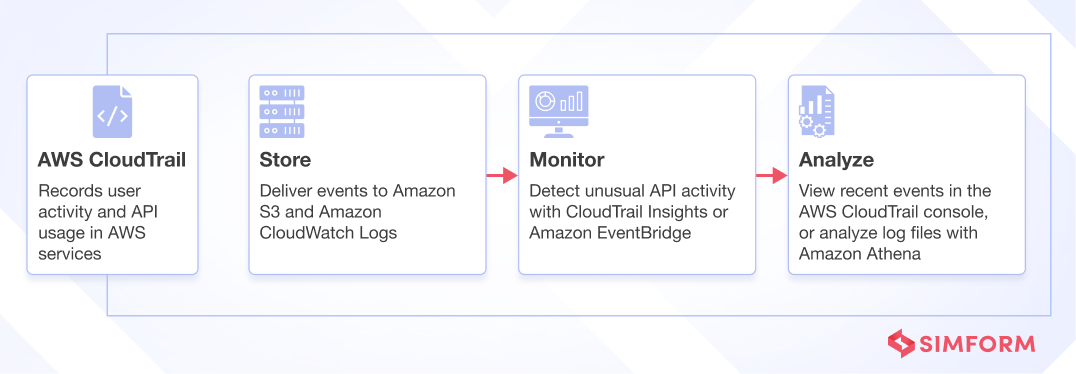 AWS CloudTrail records API calls made to provision or alter AWS infrastructure that applications depend on. These API logs provide an audit trail of changes to resources and permissions to aid diagnosis and recovery if issues emerge. By determining the identity, source, timing, and parameters for infrastructure shifts, CloudTrail logs enable tracing problems back to the change that impacted application stability. This essential visibility and causality tracking facilitate rapid remediation and infrastructure hardening for greater fault tolerance.
AWS CloudTrail records API calls made to provision or alter AWS infrastructure that applications depend on. These API logs provide an audit trail of changes to resources and permissions to aid diagnosis and recovery if issues emerge. By determining the identity, source, timing, and parameters for infrastructure shifts, CloudTrail logs enable tracing problems back to the change that impacted application stability. This essential visibility and causality tracking facilitate rapid remediation and infrastructure hardening for greater fault tolerance.
- Amazon OpenSearch
OpenSearch facilitates analyzing application logs in real-time to identify issues proactively vs. reactively. It ingests high volumes of app data to execute dashboards, alerts, and visualizations to gain visibility into workload health, trends, and anomalies. By leveraging OpenSearch’s analytics capabilities, you can monitor application metrics, usage patterns, and failure warning signs to continually tune and harden systems for resilience.
Monitor infrastructure health and application performance
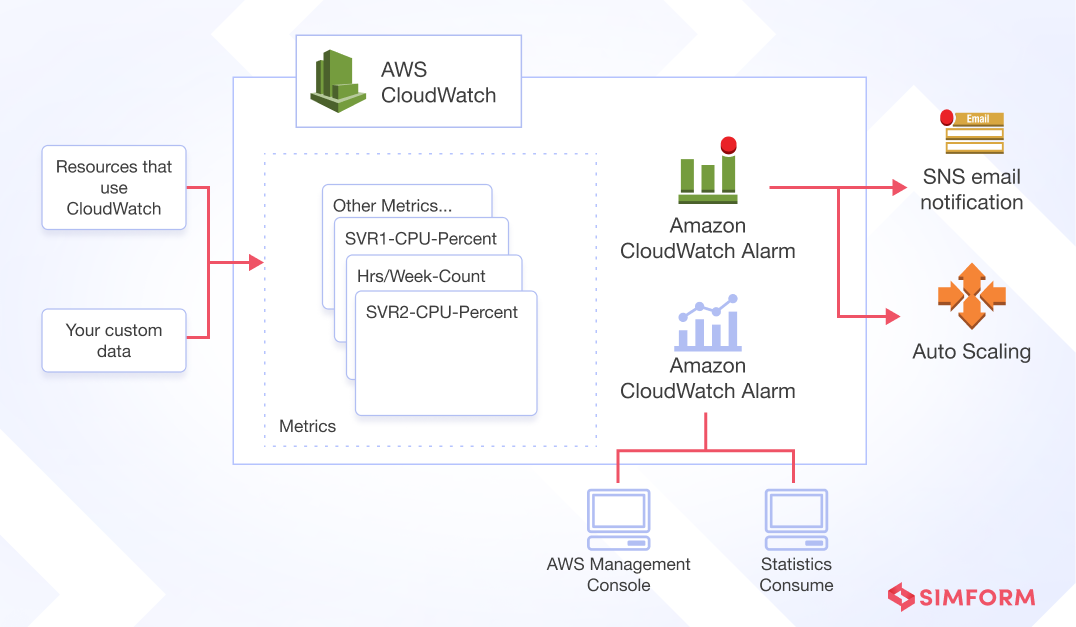 Robust monitoring provides the necessary observability into overall infrastructure health, application performance metrics, and emerging issues required to ensure resilient application architectures. AWS offers integrated tools catered for tracing system-level KPIs as well as application requests end-to-end.
Robust monitoring provides the necessary observability into overall infrastructure health, application performance metrics, and emerging issues required to ensure resilient application architectures. AWS offers integrated tools catered for tracing system-level KPIs as well as application requests end-to-end.
- Amazon CloudWatch
Amazon CloudWatch enables real-time monitoring of AWS services through customizable dashboards depicting infrastructure performance. CloudWatch alerts when metrics fall below configured thresholds, allowing rapid detection and remediation of emerging issues. This visibility into fluctuating resource utilization facilitates proactive optimization and resilience.
- AWS Trusted Advisor
Additional services such as AWS Trusted Advisor can be implemented to monitor your application with the intent of optimizing AWS cloud costs and performance. As the name suggests, AWS Trusted Advisor constantly monitors your application to look for areas that can be optimized further to improve performance or reduce operational costs.
- AWS Personal Health Dashboard
AWS Personal Health Dashboard (PHD) allows you to quickly evaluate your system’s critical health and performance metrics at once. AWS PHD gathers the information and data from other active AWS resources spread across multiple regions and displays them on a simple, customizable dashboard. It also delivers proactive recommendations to improve the performance and health of your systems to help make your application more resilient based on collective metrics.
Implement automatic remediation
Automatic remediation solutions are necessary, as they give your application the fastest chance at recovery from any technical issues. Having an automatic remediation system in place basically makes your application immune to simple errors, as the dedicated services connected to the application execute actions to fix the problems automatically.
- Amazon CloudWatch Events
To set up an automatic remediation system, you can use Amazon CloudWatch Events, which actively monitors all the events that take place in your application and triggers actions if certain predefined events take place. These actions include sending out notifications to teams or executing remedial actions.
- AWS Lambda
Amazon Lambda is a serverless computing service from AWS that is able to deploy code instantly in response to a CloudWatch alert triggered by preset event rules. When triggered, the Lambda functions can take various actions to remedy the present issues, including restarting or scaling resources when they become unavailable and failing over to backup resources when the primary systems aren’t functioning optimally. This way, the remediation process is completely automated and instantaneous.
- Amazon SNS
Amazon Simple Notification Service (SNS) acts as a communication bridge between monitoring systems and developers. Whenever an alert is detected from monitoring services such as Amazon CloudWatch, SNS automatically sends out notifications to multiple endpoints or users at once. These notifications can be configured for specific events, such as a system outage, to make your response to critical issues much faster and more precise.
Leverage AWS Well-Architected framework
The AWS Well-Architected framework provides a set of guidelines and best practices focused specifically on cloud architectures across areas (pillars) like security, reliability, performance efficiency, and cost optimization.
Adopting the Reliability Pillar principles and priorities ensures architecting for resilience against both infrastructural and application-induced failures. Key focus areas include recovery planning, the ability to withstand workloads and load spikes, and fault isolation to avoid cascading failures.
The framework also stresses detecting failures early through monitoring, understanding tolerances via game days, and embedding self-healing capabilities via automation. Continually evaluating architectures against the Well-Architected lens highlights improvements to meet availability, durability, and resiliency goals over time.
Built resilient applications powered by AWS for your applications with Simform
As organizations embrace cloud-native development and cloud infrastructure automation, leveraging AWS purpose-built services and following resilience best practices empowers teams to meet stringent availability SLAs. Simform as an AWS Premier Consulting Partner with multiple AWS Competencies is uniquely positioned to provide ongoing guidance on architecting resilient systems on AWS.
Our 200+ certified AWS cloud architects design systems sustaining real-world failure scenarios based on learnings from conducting numerous Well-Architected reviews. We empower you to exceed your SLAs through geo-resilient reference architectures, recovery automation, and instilling availability best practices at each development stage.
Our demonstrated expertise spans:
- Executing Well-Architected Reviews to continuously improve system and application fault tolerance
- Building availability testing suites focused on recovery procedures and durability
- Implementing observability tooling for deeper insights into failure events
- Providing optimized designs for multi-region active-active resilience
- Ensuring seamless failover capabilities across AZs for near-zero RTO
- Delivering automated deployment workflows preventing drift or instability
Make Simform your trusted advisor for resilience on AWS. Our partnership ensures you build with availability in mind from day one to maximize the outcomes of your cloud investments. Connect with us for a quick consultation call.