Right now, every company, no matter the size or industry, is using AI differently. According to Statista, the AI market will increase to almost 740 billion USD by 2030 from 241.8 billion USD in 2023. From optimizing supply chains to providing personalized recommendations, companies using AI are pulling ahead of the competition.
For example, 6sense uses AI and machine learning to predict revenue and guide targeted prospect outreach for B2B clients. By implementing an AI-powered conversational email tool to personalize messaging, 6sense achieved a 10% increase in new pipeline generation – showcasing how strategic AI adoption fuels business growth.
However, simply adopting AI tools is not enough to realize benefits – following best practices in building AI systems is crucial. In this article, we cover the steps to build an AI system.
How to make AI: A step-by-step process
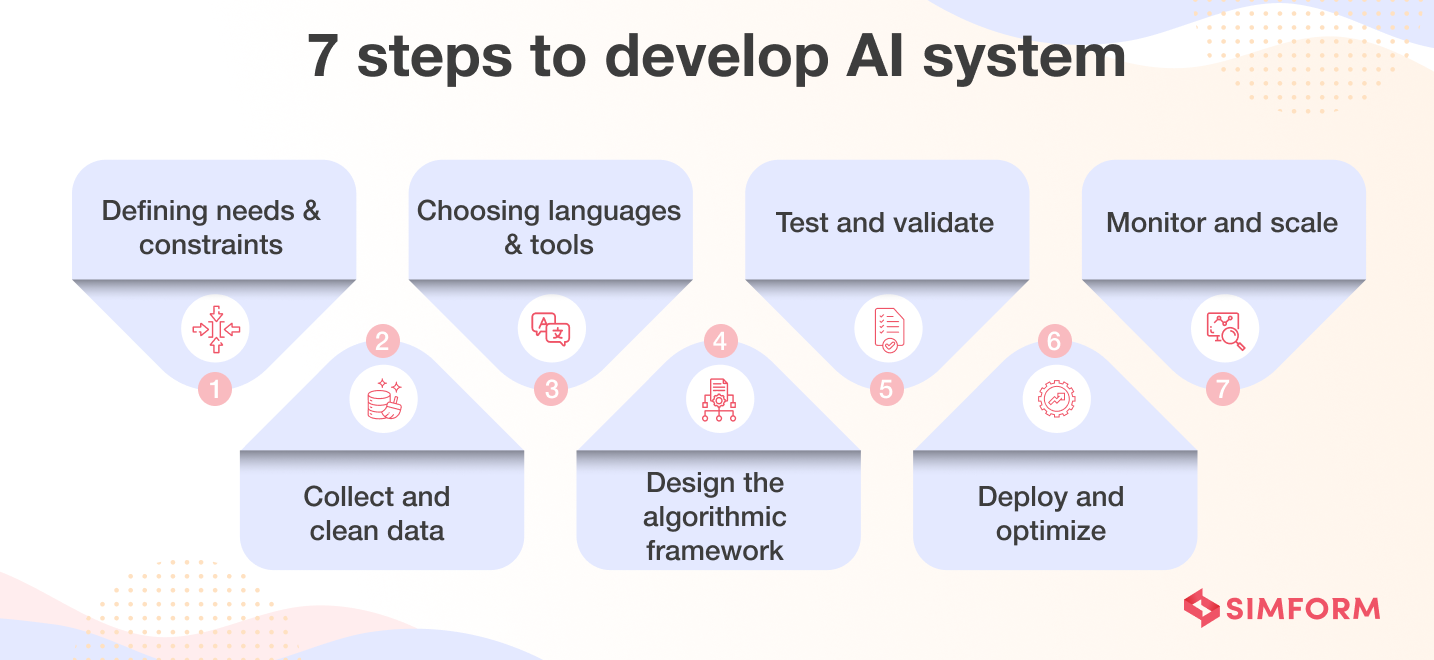
1. Understand the problem space and feasibility
The first step for developing an AI system is to clearly define the problem you want to solve and assess the feasibility of an AI solution. Ask and figure out the answers to questions like:
- What issues must we solve in our business operations or offerings? What are current pain points and inefficiencies?
- What outcomes are we hoping to achieve? How will an AI solution add value for customers or internal teams?
- What constraints do we need to operate within regarding budget, human resources, technical capabilities, etc.?
Identify if you’re looking to automate repetitive tasks, enhance decision-making with predictive analysis, provide personalized customer recommendations, or achieve some other goal. The problem definition will guide your solution architecture.
It’s also important to identify AI’s limitations. It is one tool among many to solve problems, a helpful yet limited tool for tackling issues. Assess whether AI techniques like machine learning, computer vision and natural language processing appropriately address your business objectives.
2. Collect and clean data
High-quality training data is important to develop accurate AI systems. However, data integrity issues like silos, inaccuracies, and inconsistencies are common challenges that organizations face.
First, collect datasets that capture the diversity of the problem space. These raw data can be used to solve a variety of problems, such as image recognition, speech recognition and problem solving. Compile the data from internal sources like customer records and external sources like open government data.
Next, clean and preprocess the structured and unstructured data. This includes handling missing values, removing duplicates, dealing with outliers, and normalizing features. You can use Python libraries like Pandas, NumPy, and Scikit-Learn to impute missing data, encode categorical variables, and scale features. Before preprocessing, you can also visualize data for insights into distributions, outliers, and relationships using tools like Tableau and Power BI.
After initial preprocessing, continuously monitor processes to maintain high standards. Set up validation pipelines to profile new data and check for anomalies. Use statistical process control tracking to detect deviations in data streams and natural language processing to scan text data for variations.
Additionally, configure alerts when key quality metrics breach thresholds. Conduct periodic checkpoint tests to keep sampling criteria and error rates within bounds. These practices allow ongoing, controlled updates to meet high-quality criteria throughout the AI system’s lifetime. The result is accurate training data that leads to more effective models.
3. Choose the right tools and programming languages
The appropriate frameworks, cloud platforms, and programming language options should align with your project’s scale, complexity, and specific goals.
For programming languages, options like Python and R have simple syntax and built-in libraries well-suited for tasks like data wrangling and analysis. C++ is the better choice when you need to optimize performance for data-intensive applications like autonomous driving.
When selecting cloud platforms, go for a platform offering all the cloud-based machine learning services, as it allows quick experimentation and scalable deployment. Leading providers like AWS, Azure, and GCP offer on-demand access to GPU clusters, storage, and other resources.
Plus, while choosing frameworks, consider their technical capabilities in areas like:
- Supported machine learning methods
- Hardware acceleration support
- Compute resource management
- Built-in libraries
- Monitoring and debugging tools
- Deployment options
- Programming language compatibility
- Community support
TensorFlow, PyTorch, Keras, and others have pre-built modules that quickly get you up and running. Also, they distribute training across clusters and hardware accelerators like GPUs.
4. Design the algorithmic framework
The algorithmic framework is a blueprint that guides the AI system in solving the problem. It involves selecting the most suitable machine learning algorithms based on the nature of the problem, which enables the model to identify patterns and learn from the data.
Data scientists and engineers commonly use regression and random forest algorithms for prediction tasks. Classification tasks employ models like logistic regression and support vector machines. The choice of algorithm should align with the complexity and structure of the data.
Once the framework is established, the next step is to feed the prepared data into the model for training. Then, fine-tune the model’s performance metrics through successive iterations. It’s like a feedback loop that adjusts the model’s parameters based on its performance in each iteration. In some cases, additional data may be required to achieve precise models.
A crucial part of the training process is ensuring the model’s accuracy surpasses the minimum thresholds. For example, an account fraud detection system could assign accounts a “fraud score” ranging from 0 to 1, flagging accounts with a score above 0.9 for fraud team review.
The model architecture and data inputs may need refinement until the model’s predictive capability meets the requirements. Algorithms that are well-designed and tailored to the specific use case can significantly enhance the accuracy of AI applications.
When evaluating performance, monitor metrics such as precision, recall, F1 score, and area under the ROC curve (AUC-ROC) for classification problems. For regression problems, metrics like mean absolute error (MAE), root mean square error (RMSE), and R-squared provide insights into model efficacy to guide the optimization process.
5. Test and validate
Thorough testing is necessary to avoid unexpected issues when AI models are deployed. A key practice is to set aside a subset of representative unused data to evaluate model performance rather than training.
Cross-validation further improves testing by assessing model accuracy across different partitions of the held-out data. This provides a more rigorous data analysis than focusing on just one data subset alone. By validating multiple data slices, deficiencies become clear before launch.
With the right technology partner, you can prioritize validation using key metrics – accuracy, precision, recall, and F1 scores. These offer insights into a model’s capabilities and limitations. An error analysis further uncovers areas needing improvement.
Testing and validation form an ongoing loop: train, test, analyze, adjust, repeat. This iterative process continues until the model hits target metrics consistently. AI reliability requires rigor – not just before launch but continual oversight after deployment.
6. Deploy and optimize
Once validated, AI models must integrate into real-world products and scale up. For this: prepare models for deployment by optimizing performance and converting them to production-ready formats. Smooth integration with existing infrastructure is vital – plan meticulously to enable operational synergy. For a retailer, this could mean connecting an AI-driven product recommendation engine to e-commerce and inventory systems.
Also, ensure the AI model can scale under increased usage. Implement robust monitoring to catch performance dips, unexpected behaviors, or misinformation outbreaks caused by model limitations. Promptly tune and retrain models as new patterns emerge post-launch.
7. Monitor and scale
To sustain value, implement rigorous monitoring mechanisms for ongoing performance evaluations and maintenance.
First, establish observability into system health by collecting metrics, logs, and traces. Monitor resources, prediction latency, data drift, model degradation, and component failures. Implement CI/CD pipelines to test new code against evaluation metrics automatically.
Additionally, conduct ongoing testing like A/B trials to validate new models and updates pre-launch. Track data lineage end-to-end, logging all transformations between steps. Review samples manually and link outputs to responsible models.
For debugging, perform root cause analysis by drilling into related components and metrics such as model performance indicators, pipeline failure logs, infrastructure monitoring, and upstream data validation checks. Isolate variables incrementally to pinpoint underlying issues—architect for resilience through redundancy and auto-scaling to handle spikes and failures.
To scale, build in elasticity through distributed microservices and load balancing. It creates an architecture that can flexibly respond to changes in demand. You can use auto-scaling groups on cloud platforms to dynamically allocate resources based on usage patterns. Further, break apart monolithic systems into decoupled components that can be independently autoscaled. This modular design allows incrementally scaling out specific portions of the system that need more capacity.
Similarly, optimize performance by caching frequently accessed data and using message queues to decouple processing. Batching predictions and reducing network calls can also improve efficiency.
Next, profile resource usage across the system to uncover and resolve bottlenecks limiting scaling. It involves closely tracking resource usage like CPU, memory, network, and disk I/O to find components under high load.
Identify areas nearing maximum capacity during peaks and opportunities to add/free up resources. Profiling provides the data for focused scaling decisions targeting constraints and pain points.
Both horizontal and vertical scaling may be needed to support increased demands. Horizontally scale out by adding more nodes/servers to distribute workloads. Vertically scale up by increasing server resources like CPU, memory, and storage as necessary. Take a multifaceted approach to optimization and scalability to maintain speed and reliability as usage grows.
And that’s it!
The stages of making an AI system may sound straightforward, but its implementation comes with its fair share of challenges.
Challenges in developing AI [and solutions]
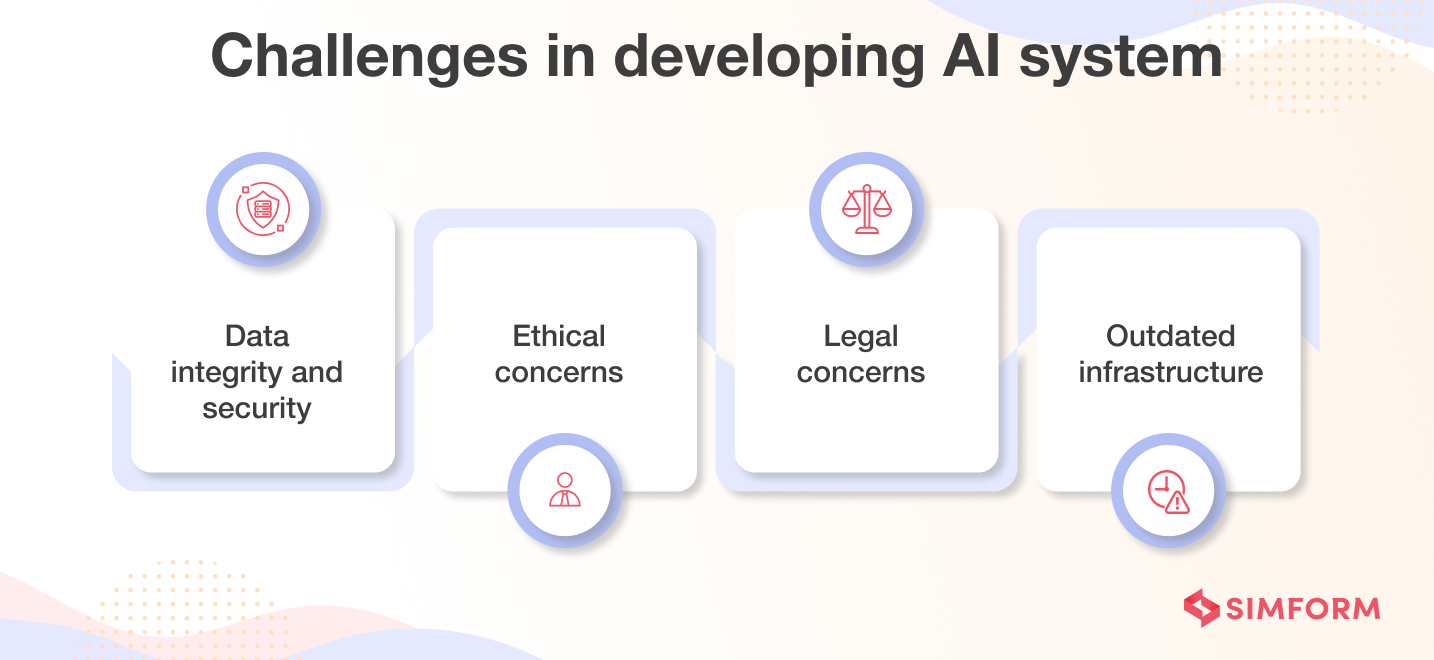
A. Data integrity and security
The quality of data used to train machine learning algorithms directly impacts performance outcomes in the real world. Without rigorous verification and data cleaning techniques, erroneous or biased data can undermine AI decision-making accuracy over the long term. That’s why continuous processes to catch new anomalies and preserve high data standards are indispensable.
Similarly, as AI handles increasingly sensitive personal data and business functions, you must implement layered defenses like access controls, data encryption, activity monitoring, and governance protocols to reduce vulnerabilities. These measures protect against unauthorized access and data theft even as adoption spreads.
B. Ethical concerns
There are two primary ethical considerations that must be addressed while making an AI system. One is mitigating bias, and the other is privacy. Without proper oversight, issues like discrimination can arise. You must also protect user data and prevent unauthorized access.
To mitigate bias, start by collecting balanced and representative data—preprocess data to remove existing biases. Choose algorithms like decision trees that avoid disparate impacts on certain groups. Evaluate fairness before and after deployment using metrics.
To ensure privacy, implement access controls and encrypt data from end-to-end. Harden environments against potential attacks.
Oversight is also important to enable ethics and compliance in AI systems. Explain outputs through methods like Local Interpretable Model-Agnostic Explanations (LIME) and SHapley Additive exPlanations (SHAP) that increase interpretability. Include human reviews to validate predictions. Continuously monitor models over time to detect changes.
C. Legal concerns
Issues around data privacy, algorithmic bias, and regulatory compliance are major legal pitfalls to consider. Discriminatory outcomes from biased algorithms also open up enforcement actions or lawsuits.
Marketing leaders who rely heavily on AI and customer data need cross-functional teams from the start, involving legal experts, ethicists, and technical specialists.
With rigorous reviews by these diverse experts, you can identify problems early and take steps to mitigate legal concerns.
You can anonymize customer data to protect data privacy. You can also run regular bias checks to catch any discrimination issues early so they can be fixed before launch. Conduct ongoing compliance audits to ensure adherence to relevant regulations. These practices will help you maintain an easy monitoring process.
D. Outdated infrastructure
Many organizations still rely on old devices, applications, and networks that are unlikely to meet AI’s processing needs. Accelerating operations with AI requires high-performance capabilities. It necessitates revamping infrastructure to new quality and efficiency levels.
Develop a strategic roadmap for phased upgrades for a smooth transition from legacy systems to state-of-the-art architectures, which improves both quality and efficiency for AI integration.
Best practices for AI software development
Developing effective AI-powered applications requires thinking beyond just algorithms to encompass the entire software lifecycle. Here are key techniques for developing artificial intelligence systems.
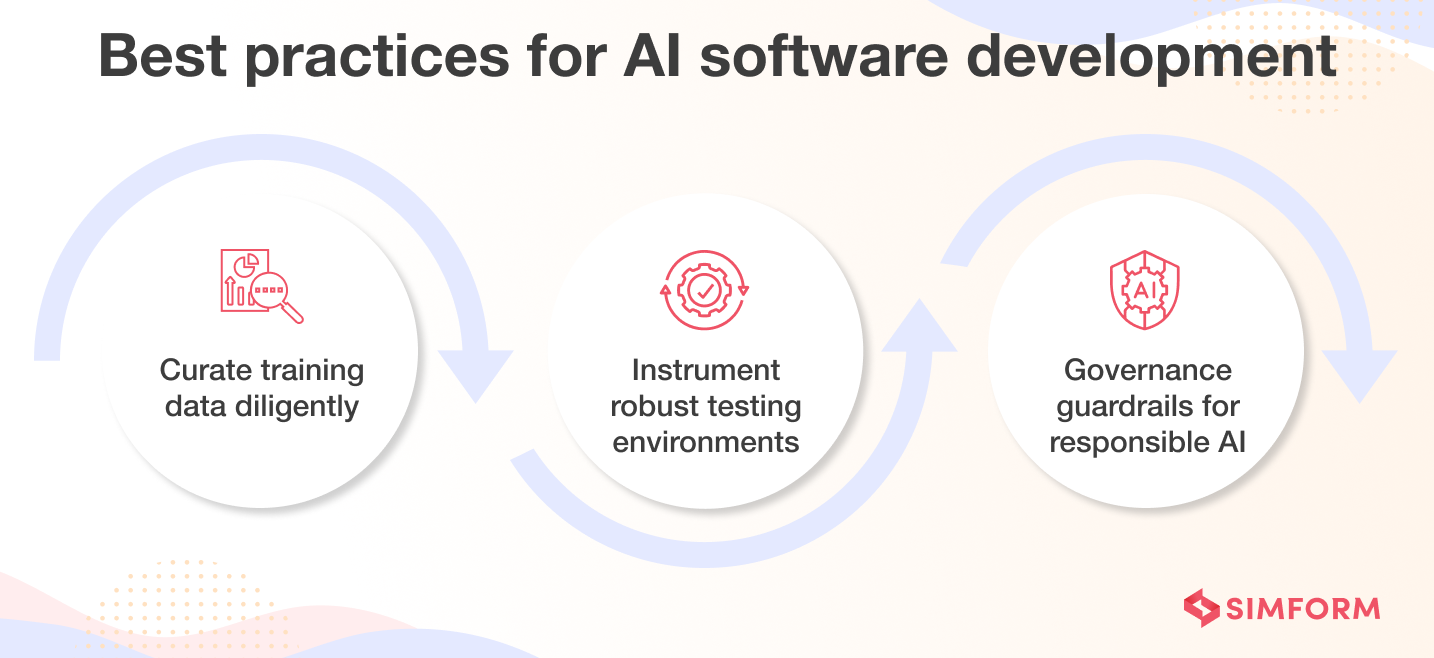
1. Curate training data diligently
Careful data curation is essential when building natural language processing systems susceptible to biased or offensive outputs. Representatives from minority demographic groups should participate in data labeling and reviews. For computer vision datasets, consider whether visual perspectives skew toward certain races, genders etc. Plan data quality checks before launches plus continuous retraining cycles with diversified data to sustain model integrity over time.
2. Instrument robust testing environments
Thoroughly testing AI systems is very important for developing safety-sensitive applications like self-driving vehicles. Self-driving models require expansive training data and simulation environments accounting for challenging situations like weather extremes, unexpected obstacles, faded road paint, complex intersections etc. Architecting modular virtual testbeds focused specifically on risky scenarios helps technologists uncover model deficiencies prior to live deployment.
3. Governance guardrails for responsible AI
Guardrails that guide models back to reasonable behaviors make the most impact for AI informing high-stakes decisions in finance, healthcare etc. If a mortgage risk model suddenly swings approval rates or a medical diagnostic tool drastically shifts disease predictions, these could profoundly impact peoples’ lives. Data validation, caps on outlier predictions, and human-in-the-loop oversight create critical safeguards against potential harms from unexplainable model volatility.
Prepare your business for AI future
The possibilities with AI systems are rapidly expanding, but risks remain. While explainable AI and multi-modal learning point to more advanced capabilities, unchecked false information and fabrications by generative AI and large language models present dangers that cannot be ignored.
Balancing innovation with responsibility is important. Adherence to ethical principles through rigorous testing, bias monitoring, human oversight, and fine-tuning of LLMs must be prioritized. You must also align business objectives, follow best practices, and future-proof AI investments through strategic thinking and technical expertise.
The AI experts at Simform can help you with ethical, practical AI plugins tailored to your business needs. Schedule a free consultation with our team to implement AI the right way.