With more than 75 million active users monthly, Spotify struggled to deploy iterations and scale the platform. Rearchitecting its platform was inevitable and, as a result, they settled with the microservices architecture eventually.
Spotify formed 90 “tribes” consisting of autonomous full-stack teams, each made up of several cross-functional squads with similar feature areas.
Subsequently, it employed the single responsibility principle (SRP) for streamlined code development to provide these tribes with enhanced autonomy.
Additionally, the company leveraged separate datastore design patterns for enhanced autonomy. Currently, Spotify manages more than 810 services with improved scalability, availability, and flexibility.
Spotify’s approach was one of the many microservices design patterns to choose from when developing an application. But when it comes to choosing one, you need to consider your business needs among others.
This article discusses the top ten microservice design patterns to help you make an informed decision.
What are microservices design patterns?
A microservice consists of independent app components that perform specific functions for a system. It may have a single instance or multiple instances based on the functional requirements.
Together with the client-side (web interface and mobile UI) and other integrated services in the intermediate layers, each of these microservices forms a complete architecture.
However, designing, developing, and deploying such microservices architecture comes with challenges like,
- Managing shared access
- Data consistency
- Security of services
- Communication between services
- Dependency management
Enter Microservice design patterns! These are reference architectural patterns that help you inefficient administration of these services, overcome these challenges, and maximize performance.
Moreover, a correct design patterns in microservices for your use case can help increase component reusability which eventually aids in reduced development time and efforts. Over time, reusability eliminates the need to reinvent the wheel each time you make changes to your application.
Top 10 Microservice Design Patterns
A Microservice design pattern is not a silver bullet though! Every design pattern has its caveats and benefits. Let’s understand each one of them in detail.
#1. Strangler pattern
Martin Fowler originally introduced the strangler pattern in 2004 with the “StranglerFigApplication” blog post.
Maintaining the application availability can be challenging when migrating an existing application to microservices, but the Strangler pattern helps you tackle this efficiently.
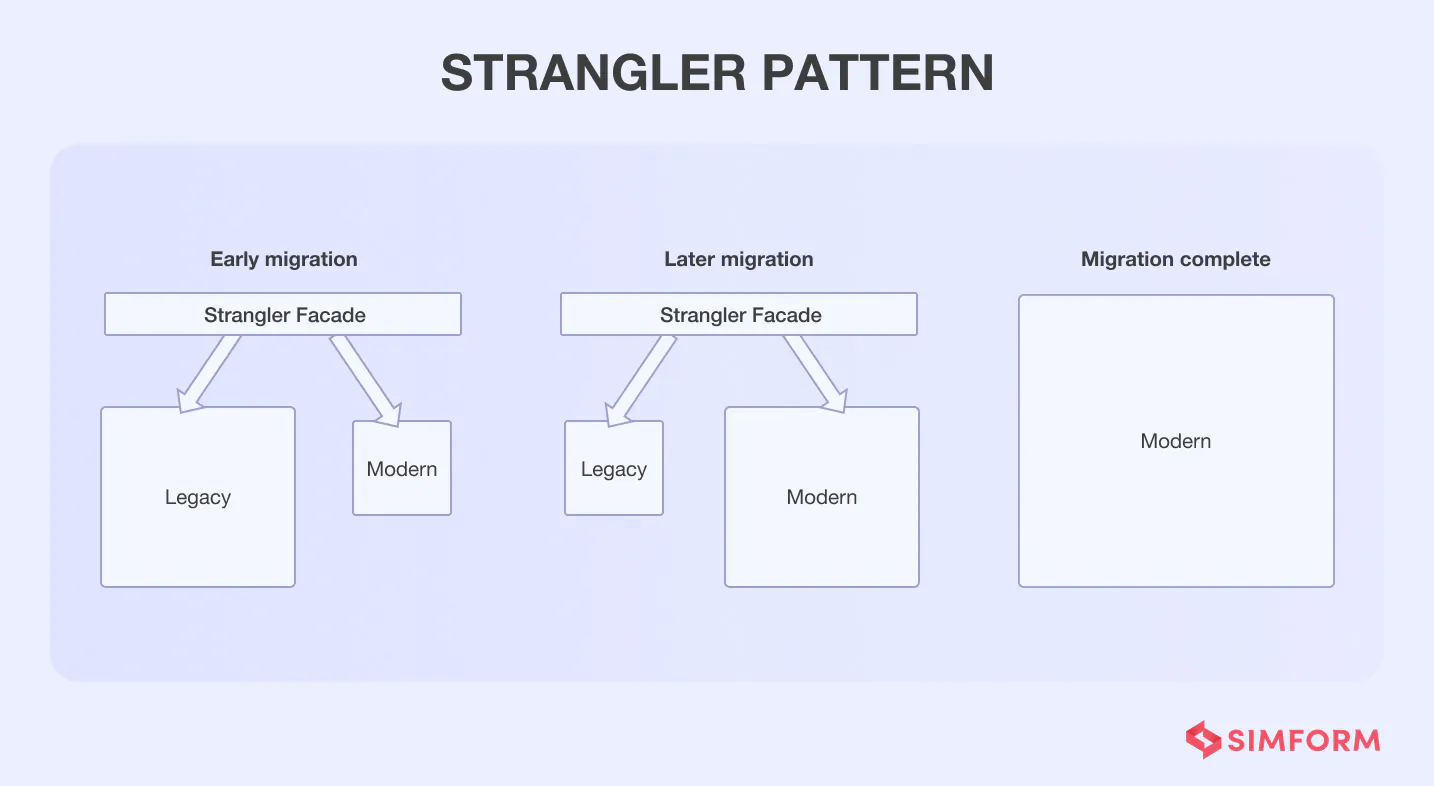
This pattern allows an incremental and reliable process of refactoring code. It describes a method where the team moves specific functionalities, one at a time, with a new microservice.
The best part is that changes are incremental, monitored at all times, well-defined and the chances of things going wrong are pretty low.
Therefore, when application availability is one of the top-most priority, this pattern works best and also it ensures building a system that already has a good test coverage in place.
During migration, an API Gateway acts as a facade which directs users’ requests to the correct application.
Having such a facade makes sure that the application is available. Moreover, it allows development teams to migrate at their own pace without any external commitments.
Once the migration is complete, the monolithic architecture is “strangled,” in other words, the monolithic application is ready to be retired.
Shopify refactored the shop class with a strangler pattern.
One of the most critical parts of Shopify’s RoR codebase is the Shop model, which has over 3000 lines of code.
When Shopify was a smaller company, the Shop’s purpose was clear but as it grew, the company became far more complex, and the business intentions of the Shop model were all over the place.
Eventually, Shop’s definition became unclear. As an advocate of clean code and well-defined software architecture, Shopify needed to come up with a solution to tackle this. Eventually, they decided to employ the Strangler Fig pattern for refactoring.
The company knew one thing from the beginning — guaranteeing no downtime for Shopify was critical and moving to an entirely new system in one go seemed like a recipe for disaster.
This is why the Strangler Fig pattern seemed like the perfect approach. Shopify started migrating to the new system incrementally but at the same time kept the old system in place until they were confident that the new system operated as per expectations.
Additionally, Shopify laid down an in-depth 7-step process used for extracting settings front the Shop mode.
#2. Saga pattern
At the core, a microservice-based application is a distributed application with multiple granular microservices. These services work to facilitate the overall application functionality.
However, one of the major problems is how to work around functionalities (transactions) that span across multiple microservices.
The Saga pattern is one of the microservice design patterns that allow you to manage such transactions using a sequence of local transactions. Each transaction is followed by an event that triggers the next transaction step.
If one transaction fails, the saga pattern triggers a rollback transaction compensating for the failure.
Managing multiple eCommerce transactions with a Saga pattern
Here’s an example of an eCommerce application that consists of multiple transactions for orders, payment, inventory, shipping, and notifications. Once an order is generated for a specific product, the next transaction for the payment and the inventory update is initialized.
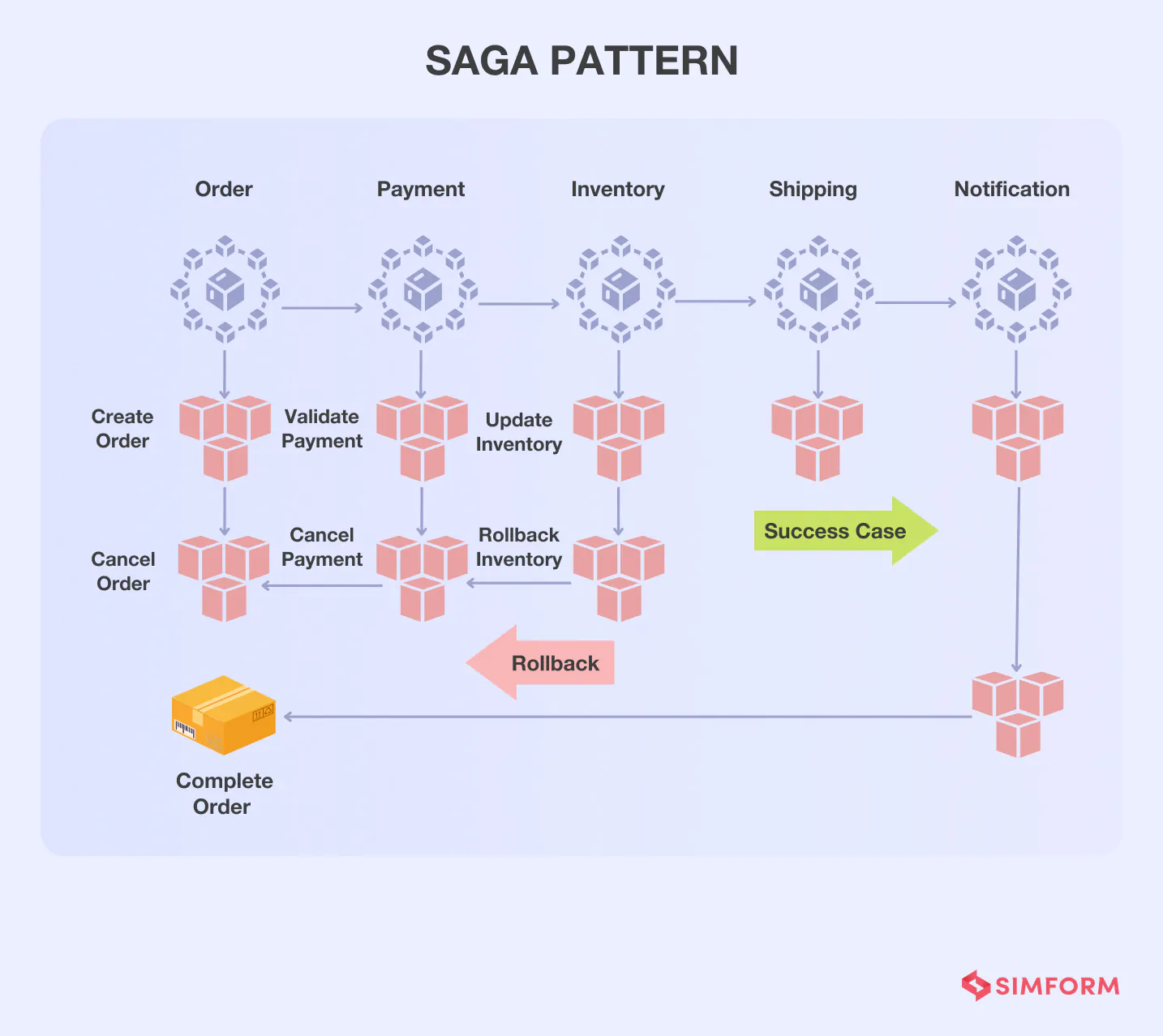
If the transaction for inventory update fails, for example, due to unavailability of a product, a rollback is triggered. If the transaction for inventory update is successful further transactions are initialized.
Moreover, Saga transactions don’t need to know about the command or the role of other transactions. This allows developers to build simplified business logic with clear separation of concerns.
This pattern is suggested for applications where ensuring data consistency is critical without tight coupling. Likewise, it’s less suitable for applications with tight coupling.
#3. Aggregator pattern
The aggregator pattern is a service that is operated in four steps:
i) The service receives the request
ii) Subsequently, this service makes request to multiple other services
iii) Combines the result from these multiple services
iv) Responds to the initial request
This pattern allows you to abstract the business logic from multiple services and aggregate them in a single microservice. So, only one aggregated microservice is exposed to the UI instead of multiple services.
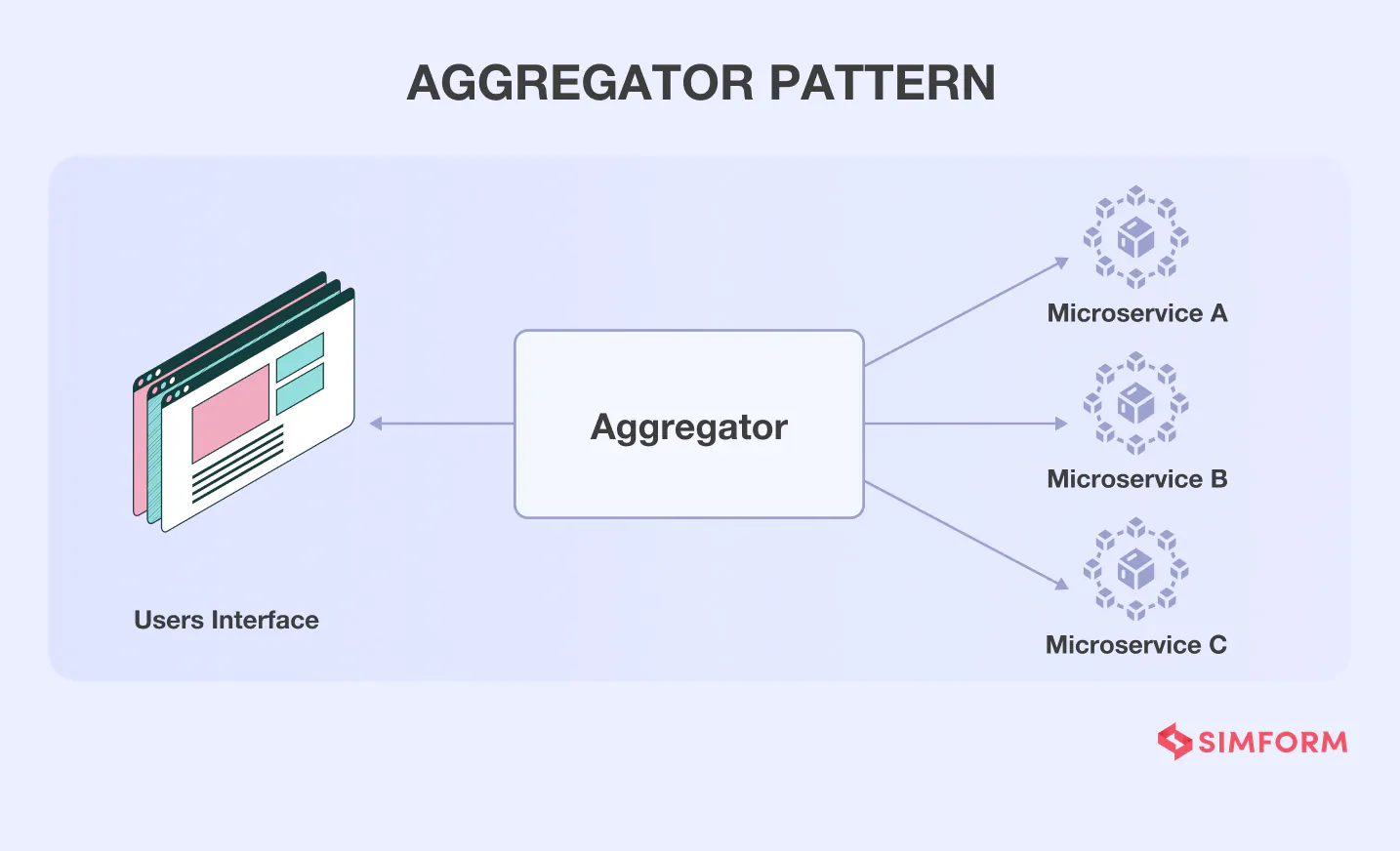
An aggregator works on separating large modules of monolith applications into small but atomic parts, provided these atomic parts have autonomy and ability to work independently.
The major benefit of this pattern is reduced communication overhead between the client and services, especially where the client has a limited bandwidth. Moreover , this is easy to understand and implement, which enables faster time to market.
Though the major drawback is the multiplicative effect of failure, and increase in latency of responses as a result of involvement of multiple microservices.
Grade calculations for an e-learning platform with the aggregator pattern
An online e-learning platform has an application for calculating grades of different online tests. There are two microservices, one for the grades and the other for the student’s name.
Whenever a user requests for the individual’s grades, the microservices aggregates response from the two separate microservices.
Here, the business logic for calculation of grades works as a service request.
#4. Event Sourcing
The event sourcing pattern is generally used along with the CQRS pattern to decouple read and write commands. This allows the development team to optimize and achieve high performance, scalability and security.
The typical CRUD model has some limitations. For example, it can slow down performance, responsiveness and provide limited scalability due to the processing.
Event sourcing patterns help you tackle these issues by defining a meticulous approach to handle data operations that are driven by a sequence of events. For example, if you consider an eCommerce app, the creation of a shopping cart and the addition or removal of items are events.
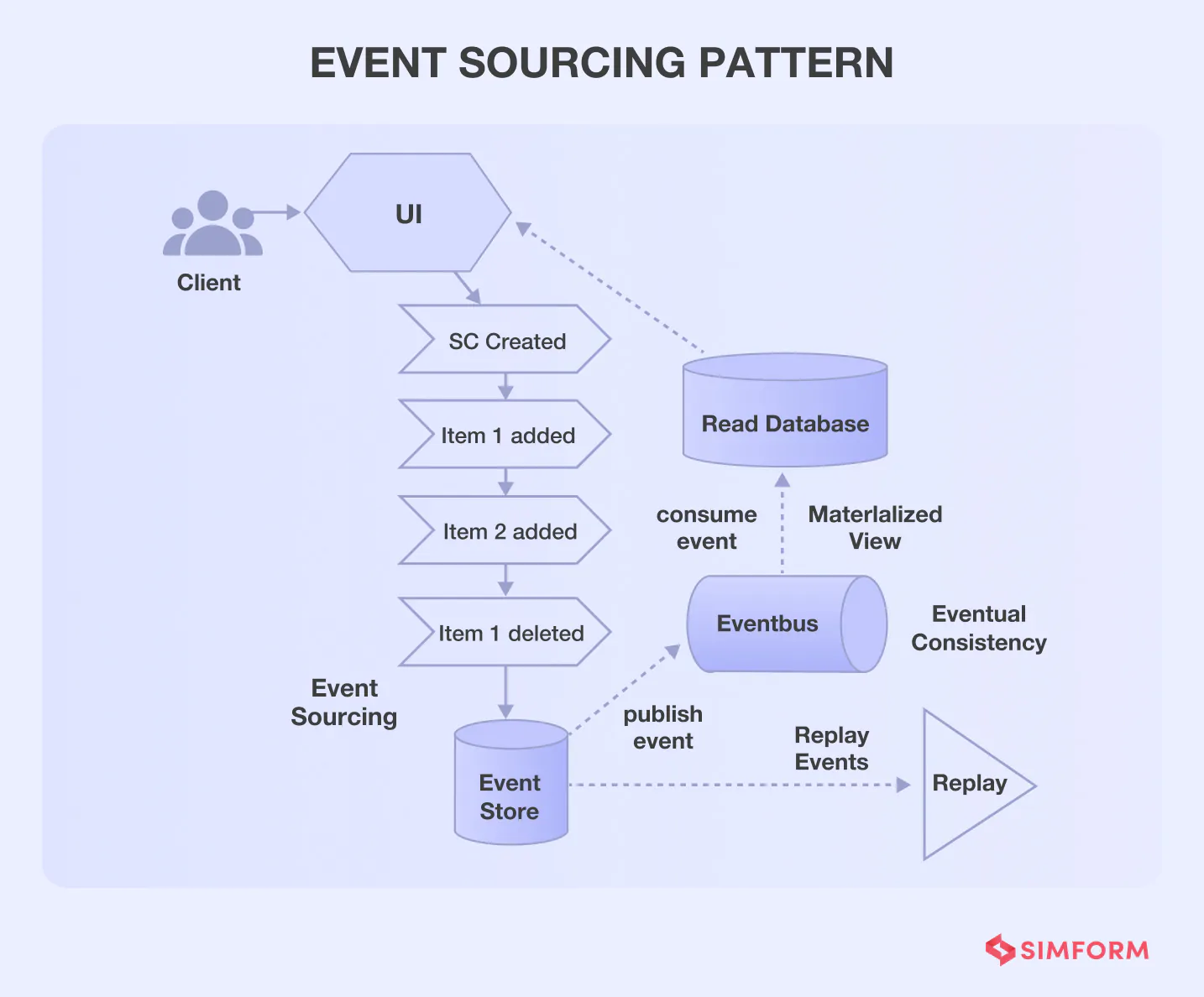
As per this pattern, every event is stored in an event store. Further, the event store adds each event to the event bus. Here, the event store acts as a message broker.
Each event is added to the messaging queue (event bus), and the event store acts as a message broker. In other words, the data record is not updated for every change; rather, an event is stored.
Further, all the events are summarized in materialized view database. It allows users to access the shopping cart status in real-time from materialized read database. As the write database stores only event actions or changes of state, the system will have a historical record for users.
So, if customer requests for shopping cart status at any time in history, the system will replay the event from write database.
Linedata used event sourcing for their flagship trading application
Linedata is a leading asset management company with more than 450 clients across 20 offices worldwide. The Linedata teams were looking to modularize their software development and wanted a flexible database technology.
One of the most significant challenges was to decrease app update time. Each time a new feature is to be deployed, the entire application needs to be updated. No wonder it made the deployment process sluggish with excess usage of resources.
After considering several design patterns for microservices, Linedata teams chose event sourcing. They needed a data storage procedure with an audit trail, root cause analysis, and real-time artificial intelligence.
Event sourcing helped them achieve this by ensuring that every change of state is captured. So, if an app is updated the historical data is not lost.
Every event is stored in the sequence as they occur which helps with complete historical data. Eventually, event sourcing helped them achieve 70-80 % quicker performance tests for each update.
With the help of this pattern, you can tackle CRUD limitations through an event-based approach, capture every update or change in the app’s state, and store each change as an event in sequence based on its occurrence.
Moreover, the materialized read database helps with real-time data access, while the events help gain access historical data through events.
#5. Command Query Responsibility Segregation (CQRS)
When you have a large application, reading data from an “Event Store” becomes problematic, especially true with the Event Sourcing pattern because it requires processing all the entities even while fetching a single entity.
In such cases, the Command Query Responsibility Segregation (CQRS) pattern becomes an ideal choice because it separates read and update operations.
This separation of concerns allows development team to adapt models that are more maintainable and flexible.
Thus, the flexibility offered by this design pattern helps the systems to better evolve over time. Eventually, CQRS implementation can help you enhance application performance, security and scalability.
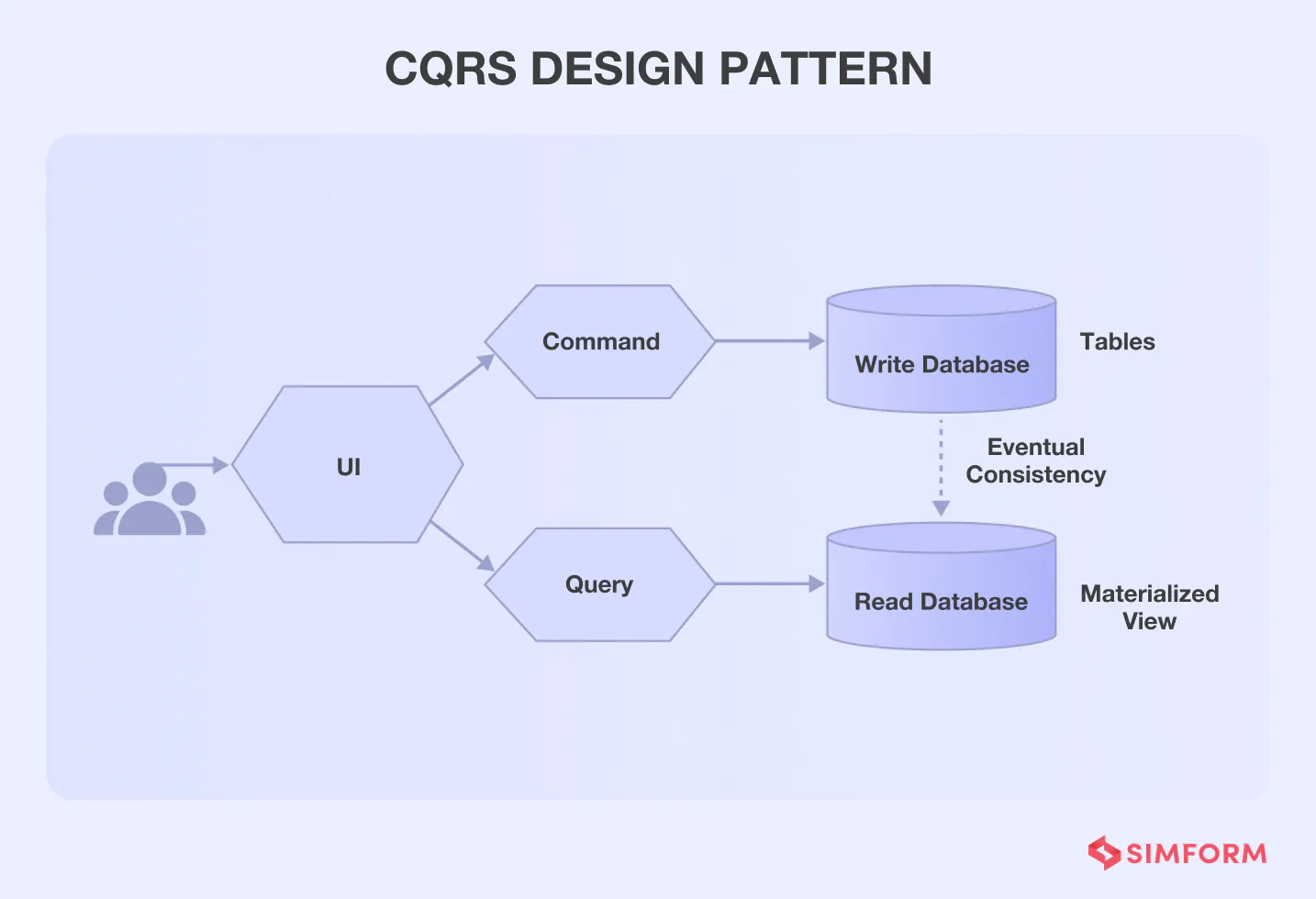
This pattern also allows you to have optimized data schemas, for example, the read side and the write side may have data schema that is optimized for queries and updates respectively.
This pattern is ideal in cases where the number of data reads is much higher than the number of data writes. In such cases, microservice design patterns like CQRS will help you in scaling the read model separately.
Instagram optimized query execution performance with CQRS
Instagram had 200 million active monthly users in 2013. Its team was storing more than 20 billion photos each month. However, two years later, the active monthly users had increased to 400 million while storing 40 billion photos serving over a million requests per second.
Supporting the data storage and executing higher requests per second was challenging. So, they decided to scale its infrastructure geographically. However, one of the challenges of geographical scaling was data replications.
With each update in write operations, the log files were updated. Every new data replica reads the snapshot of log files and streams the changes by serving read-only replicas to the web servers.
If the rate of writing data for a database is higher, the system faced a lag between log reading and creation. So, read-only replica streaming faced higher latency. Ultimately, the company used the CQRS pattern to separate the update and reading operations for each new replica.
The team created a separate streamer for new replicas that logs and stores data locally. So, each replica has a local cache for reading operations. The solution helped them achieve better query execution performance and reduce the time needed for replica generation to half.
The CQRS pattern is majorly helpful in separation of concerns, faster reading and writing of operations, improved execution of higher queries per second, and achieving individual scaling of read and write operations.
#6. Sidecar pattern
Every application needs various functionalities like monitoring, logging, configuration, etc. These peripheral tasks can be implemented as separate services. Keeping these services tightly coupled with the apps can lead to a single point of failure. So, if one component fails it affects the entire application.
On the other hand, decoupled services will provide flexibility in using different programming languages for each service. But every component has its dependencies and will need a set of libraries to use the underlying platform. Managing different dependencies and libraries for each element makes it a complex process.
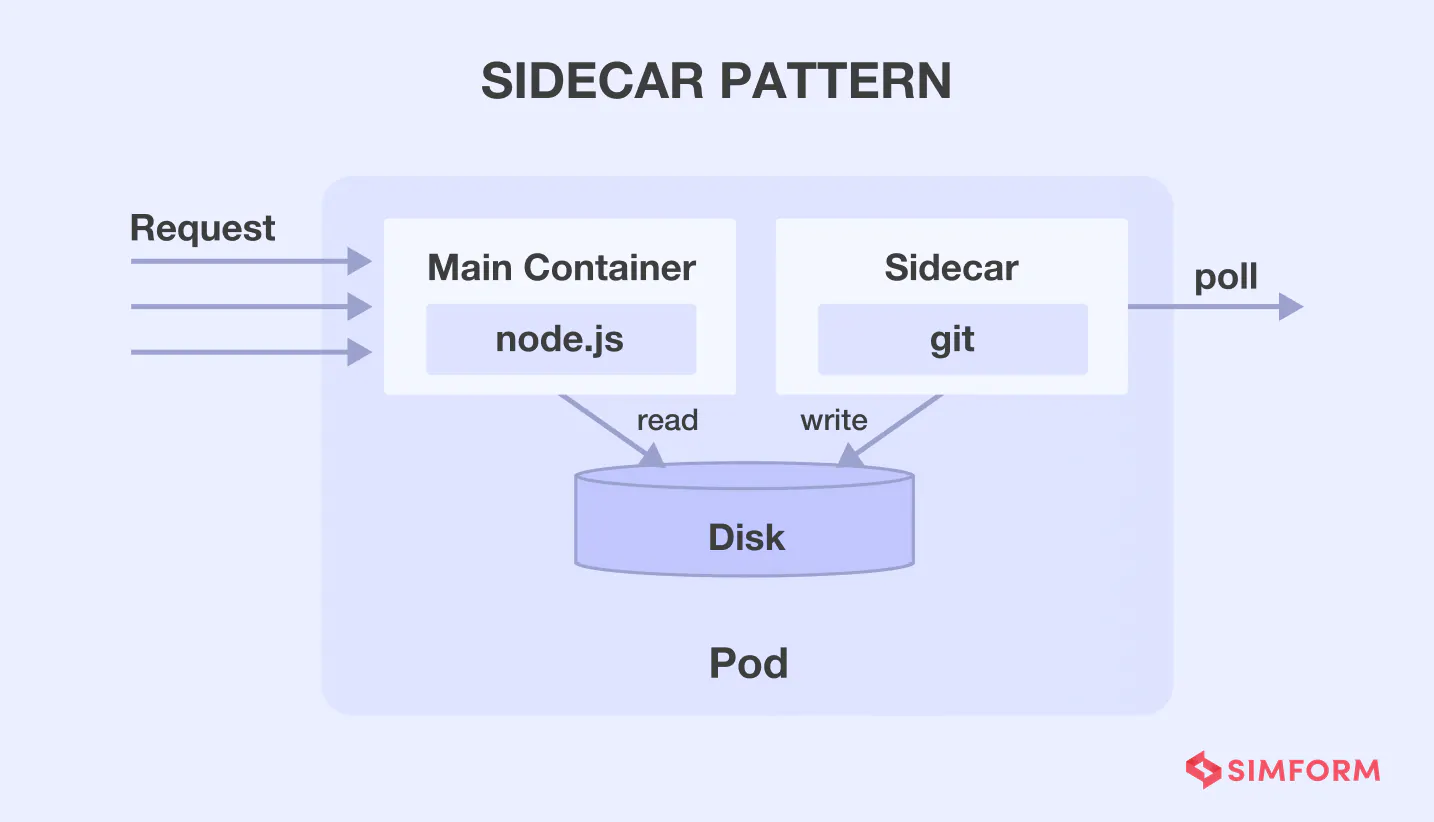
The solution is the sidecar pattern that allows you to co-locate additional services within an independent container. Both the core app and sidecar pattern can perform read and write operations with a shared file system. It will enable you to have additional services as a part of the core app without being tightly coupled.
Moderna uses the sidecar pattern to facilitate cloud-based manufacturing
One of the key use cases of sidecar design patterns is infrastructure APIs. You can create a common infrastructure layer for logging, environment data, configuration store, discovery, health checks, etc. This use case is intelligently leveraged by Moderna which uses the common infrastructure layer for communication between on-site equipment and the cloud.
It uses a Machine Learning algorithm to identify thousands of mutations in the RNA to design unique mRNA therapy. Futher, it uses AWS cloud services to run everything from manufacturing, inventory management, and even accounting.
The data exchange between on-site instruments and the AWS cloud is facilitated through infrastructure APIs. It helped them integrate Delta process control systems on-site and manage communications with Syncade manufacturing execution systems.
Smart SKIDS execute the manufacturing phase after data exchange with Syncade. SKIDS are recipes designed for specific manufacturing tasks.
#7. Database per microservice
After moving your legacy system to the microservices, the first thing that comes to your mind is the database. Using one extensive database for your microservice architecture can act as an anti-pattern due to the tight coupling of services with the database.
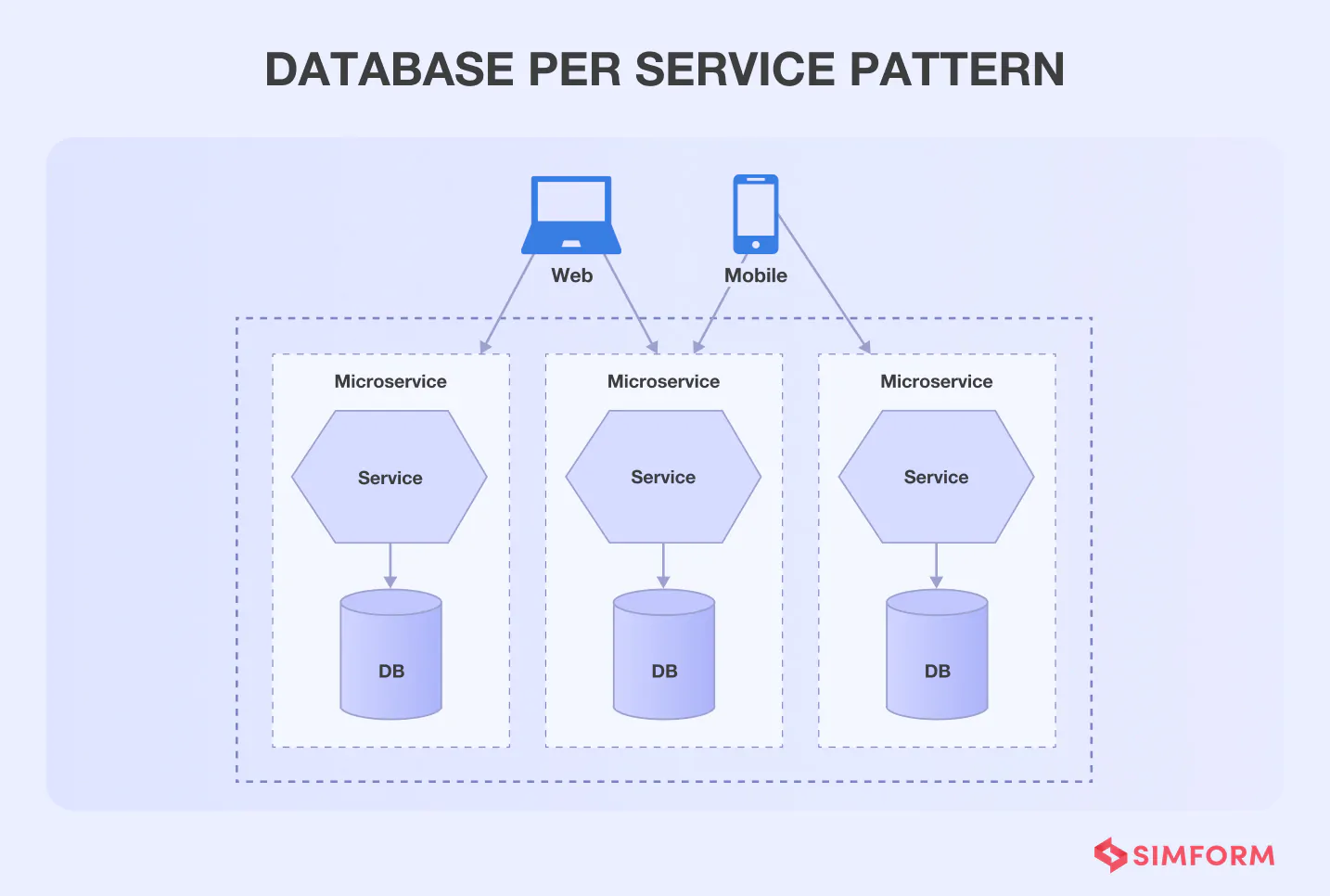
So, the solution is to provide every microservice with separate databases. Each microservice will have a data store restricted for other services.
According to Chris Richardson, there are several ways to keep the service’s persistent database private. For example, if you are using a relational database, you can use three specific options,
- Private-tables-per-service- Each service has an exclusive set of tables not accessible to other services.
- Schema-per-service- Every service has a specific database schema that is not accessible to other services.
- Database-server-per-service- Each service has its own database server
These services communicate through APIs, making the entire operation seamless.
Empowering a Credit-based financial institution with a database-per-microservice: A Hypothetical scenario
Let’s take an example of a credit-based financial service that requires comprehensive data of users. It allows them to establish financial health, credibility, and user capacity to repay loans. Data from users’ financial accounts, assets, spending patterns, income sources, and existing loans are aggregated for review.
Microservices with a shared database will have to fetch aggregated data. Each user request execution will need fetching of data from multiple sources which can lead to higher latencies and a lack of a good user experience.
For instance, if a user is calculating eligibility for a home loan and then EMI for specific tenure, the data needed for each user request will be different. Database per microservice pattern functions through individual databases based on its domain of functions. Therefore, there is a separate database for the eligibility checking app and EMI calculator.
#8. Backends for Frontends (BFF) pattern
In modern business applications using the microservices architecture patterns, you generally decouple the frontend and backend services. Instead, they communicate with each other via API or GraphQL.
For example, imagine a scenario where the application has a mobile app client and the general web client. Using the same backend microservices for web and mobile could become problematic. The reason is web and mobile applications have different requirements, such as screen size, display, performance, network bandwidth, etc.
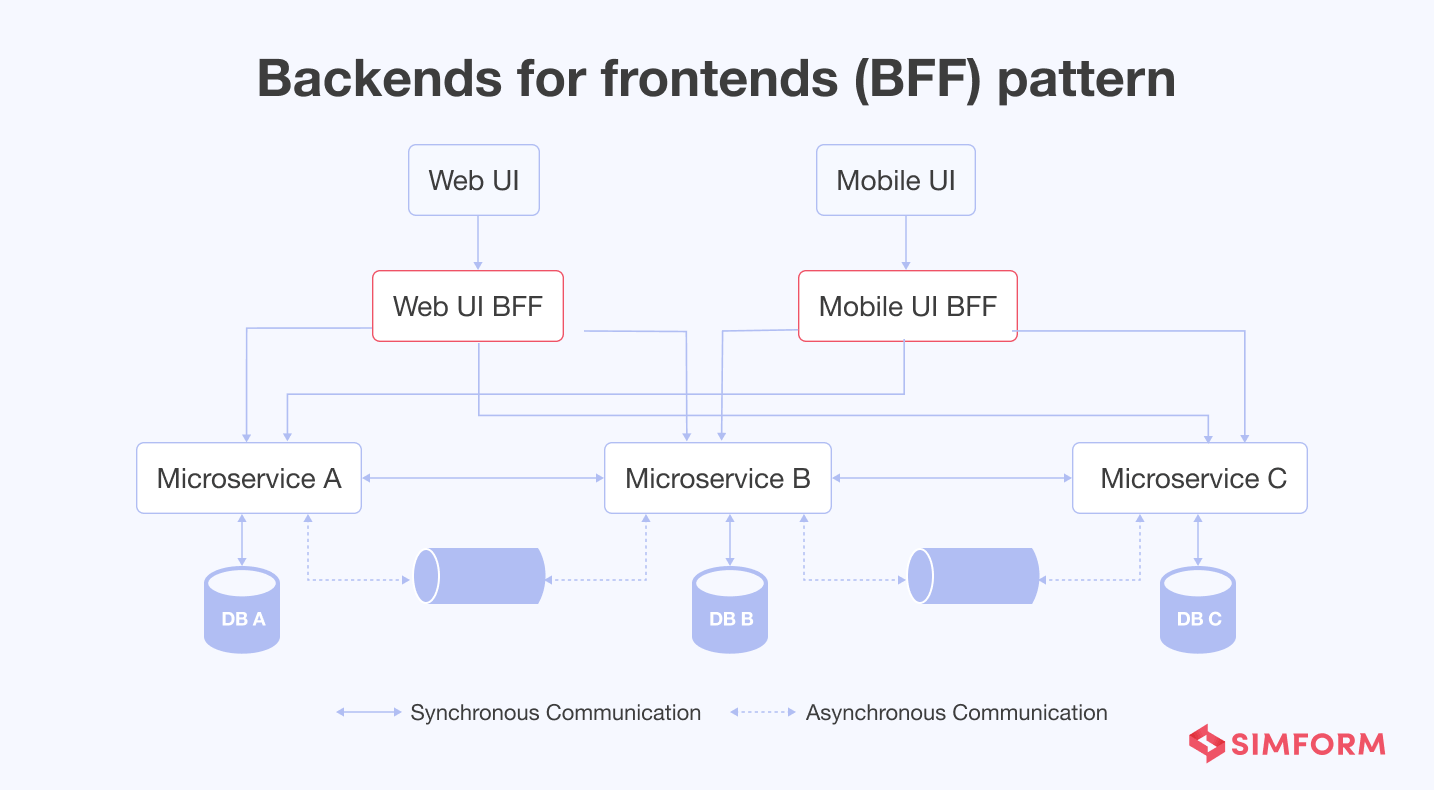
Backends for Frontends (BFF) can solve these scenarios. Each UI will get a separate backend designed exclusively for a particular UI in this pattern. The design pattern can act as a facade for downstream microservices, reducing chatty communication between UI and downstream microservices. In addition, it can help developers enhance security in microservices.
SoundCloud increased autonomy, resilience, and pace of development by adopting the BFF pattern
SoundCloud pioneered the BFF pattern way back in 2013 while moving from a monolithic legacy application with a single API to a microservice architecture. The primary reason behind the move was to scale both operationally and organizationally.
The proliferation of newer microservices paired with internal API for monolith opened the door for dedicated APIs to power the front ends. Thus, the invention of BFF took place. As of 2021, SoundCloud operates with dozens of BFFs, each powering a dedicated API. BFFs provide rate limiting, authentication, header sanitization, and cache control services.
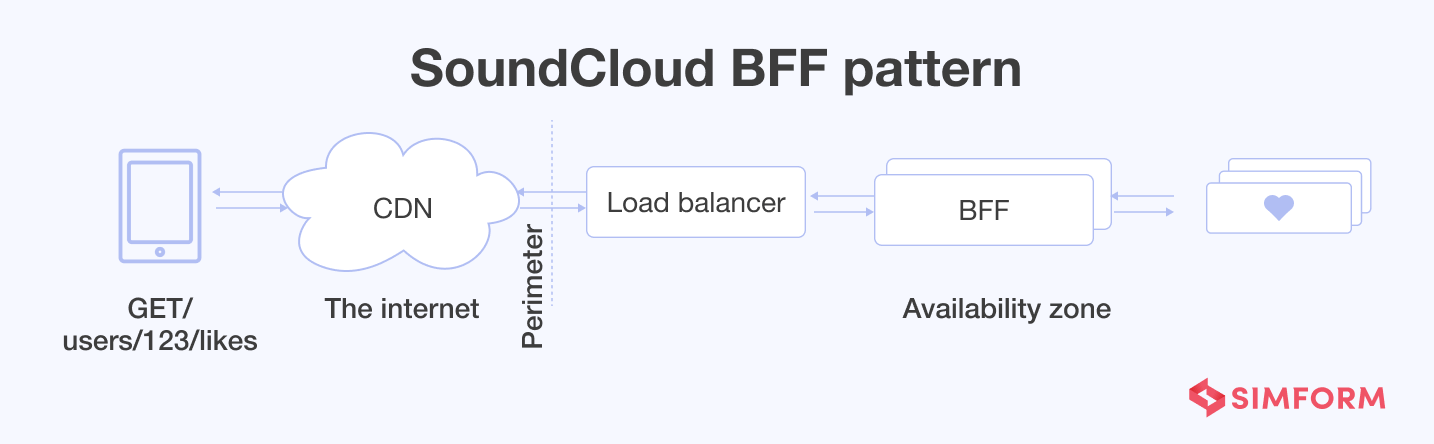
All the traffic entering the data centers of SoundCloud gets processed by one of the BFFs. They can handle millions of requests per hour. SoundCloud’s famous BFFs are mobile API (powering Android and iOS clients), web API (powering our web frontends and widgets), and public and partner APIs.
There are multiple advantages that SoundCloud leverages with the BFF pattern. First is autonomy. As the patterns separate APIs per client type, SoundCloud can optimize APIs at the convenience of each client. For example, mobile clients prefer larger responses, while web clients prefer fine-grained responses. SoundCloud could handle both scenarios with ease.
The second benefit of BFF is resilience. A lousy deployment might bring down a particular BFF in the availability zone but won’t affect the entire platform. Lastly, high autonomy and lower risk lead to a higher pace of development. SoundCloud could deploy various BFFs multiple times daily and receive contributions from the engineering team.
#9. API gateway pattern
In a typical microservice architecture, UI connects with numerous microservices. If the developers have designed the microservice in a granular manner based on specific functions, the client must communicate with plenty of microservices.
API gateway pattern can be a great solution to all such issues. It is located between the client app and backend microservices. So, the API gateway pattern works as a reverse proxy to route client requests to the appropriate microservice. It additionally supports cross-cutting concerns.
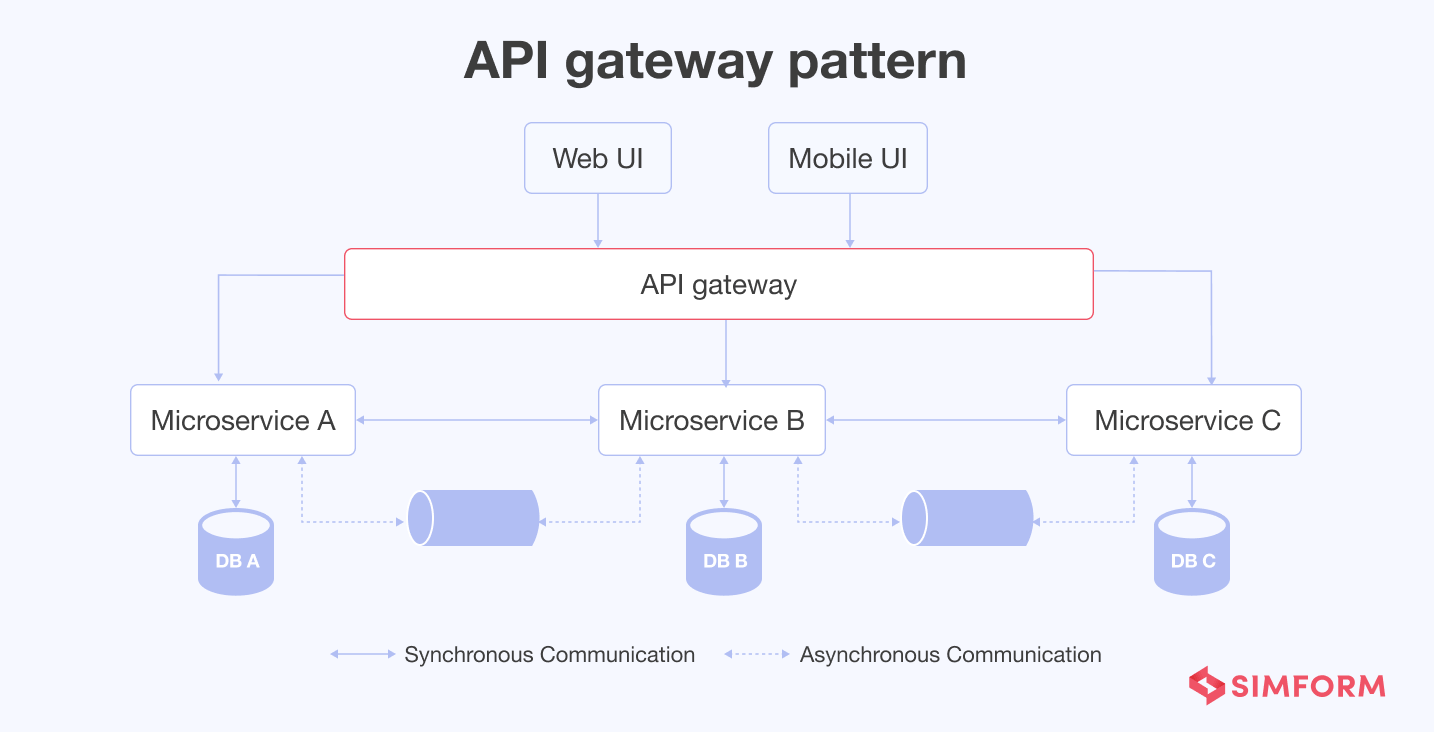
Lastly, the API gateway pattern is one of the aggregator services as it can send the request to multiple microservices and similarly aggregate the results back to clients. It acts as the entry point for microservices to reduce the number of round trips between clients and microservices. Moreover, an API gateway ensures higher security due to a single point of contact with users.
Leveraging API gateway pattern for an e-commerce platform to enhance its performance, security, and processing power: A hypothetical scenario
Consider a product page of an e-commerce platform like Amazon. It comprises lots of information that needs to get rendered for a specific page request. Hypothetically, let’s assume that Search, Inventory, Shipping, Rating and Reviews, Recommendation Engine, and Merchants are the six different microservices used for rendering purposes.
Now, these six microservices get deployed on different servers, so if the client wants to access them, they need to make six calls, which is not an appropriate solution. Making six calls would impact the performance, resource consumption, load time, etc.
Also, there is a tight coupling between the client and these six services. So, if developers want to separate Reviews and Ratings into two different microservices, they must update the client code. Also, the client must make two separate calls to access Reviews and Ratings.
The idea of an API gateway pattern comes to the fore to overcome such issues. API gateway acts as a layer between the client and microservices. Now, any client who wants to access the microservices will call the API gateway, which will reach all microservices, collect the responses, and get back to the client. This process is called API composition.
So, the API gateway pattern facilitates faster processing, decreases load time, and optimizes resource utilization. In addition, the end-user will need to make only one request, and they can get an appropriate response within a few minutes, enhancing the application’s performance. Lastly, the API gateway ensures that the client only accesses one service instead of multiple microservices, reducing the touchpoints for any malicious and DDoS attacks.
#10. Circuit breaker pattern
In a microservice architecture, a microservice generally calls the other service to fulfill a business requirement. Sometimes a call can fail due to poor network connection, timeouts, or service unavailability. Mostly retrying calls solves the issue. But, there are cases where there are several failures, and retrying is a waste of time and resources.
That’s when the circuit breaker pattern comes to the rescue. A microservice calls another microservice via proxy, similar to an electrical circuit breaker. The proxy counts the ‘number of recent failures’ to decide whether to immediately allow the operations or return an exception or service temporarily unavailable signal.
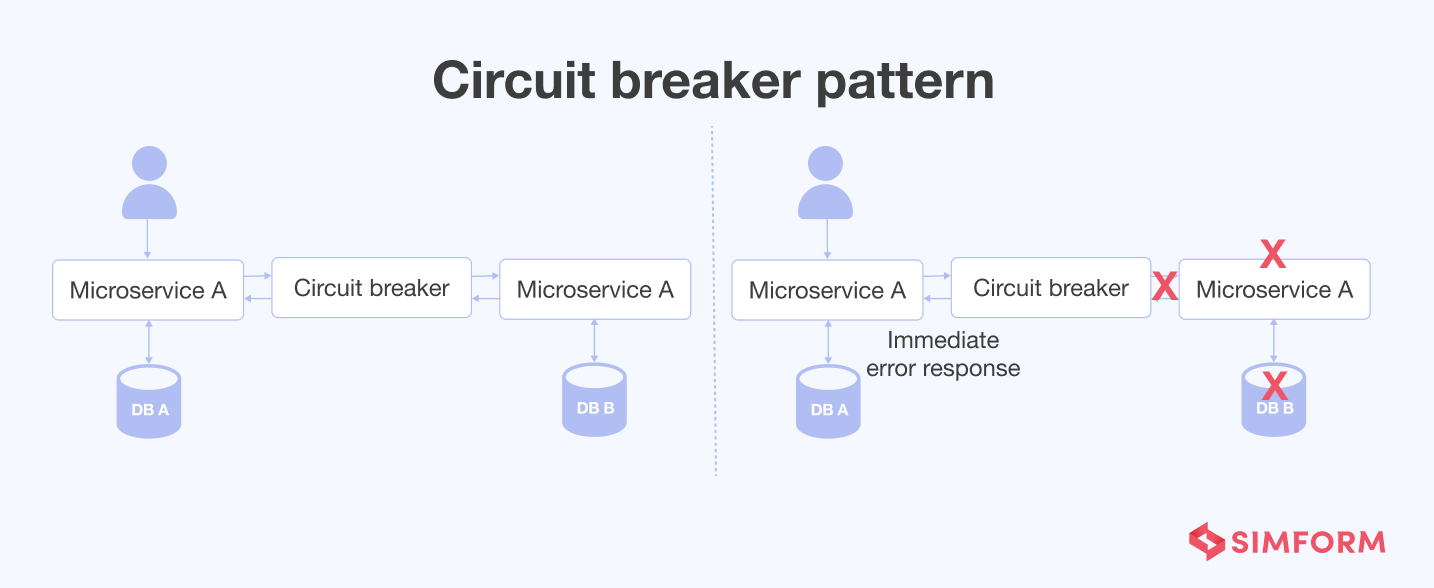
The circuit breaker pattern has three states:
- Closed: You route the request to microservice and count the number of failures. If the failure exceeds a threshold value, the service trips and moves to the Opened State.
- Opened: Request from microservice fails immediately and returns an exception. Also, after a timeout period, the circuit breaker moves to the Half-Opened State.
- Half-Opened: Only a limited number of requests get routed to microservices, and if they are successful, the circuit breaker moves to the Closed State. Otherwise, it will move to the Opened State.
Spotify improved its fault tolerance and resiliency by adopting a circuit breaker pattern.
Spotify’s backend comprises thousands of servers. At this scale, the hardware problem was the most common occurrence. Also, Spotify’s server park gets spread out across the globe. So, the network connectivity between data centers caused latency issues.
As Spotify’s backend servers comprised various microservices, an incoming request generated more requests. For example, a request to display relevant ads created a request for login to obtain personal information. If any of these requests failed, it impacted the other request and, finally, the particular service.
The engineering team at Spotify wanted to get rid of this cascading failure. On a lower level, they used exception-handling practices and error codes for effective resource utilization. However, with infrastructure as complex as that of Spotify, the solution wasn’t long-lasting. There were many cases of memory leaks while implementing exception tracking.
Finally, the engineering team adopted a fast-fail request approach and a circuit breaker pattern. It allowed Spotify to know whether a particular service was available or lagging. If a specific service lags based on the threshold value set by the developer, the circuit breaker pattern will declare that service temporarily unavailable.
So, there won’t be any more requests for that specific service, and the rest of the service can function as desired. Also, the circuit breaker pattern will check the health of the unavailable service on a fixed time interval. And whenever the service is ready to receive requests, it will allow the request for that. In this manner, Spotify created a fault-tolerant and resilient service.
How does Simform use microservices to help businesses?
We have been using different microservice design patterns to enhance business solutions for our clients. For example, the FreeWire technologies can deliver faster EV charging on-demand solutions as a result of Simform’s engineering excellence.
Our engineers used AWS with a database per service design pattern to,
- Allow all the microservices to talk to each other seamlessly
- Run services on different containers with consistency in configurations
- A combination of SQL and NoSQL database architecture to handle a large volume of data
- Hosted SQL database on Amazon RDS to take automated backup, data replication, etc.
Storage and retrieval of non-relational data through Amazon DynamoDB.
Also, automating the development process helped reduce the app development time by ten hours each week. If you are looking for an advanced microservice solution for your business, get in touch with us.
