Assuming your familiarity with machine learning – where algorithms and data enable computers to learn and decide, let’s look at the two models that emerge while applying these algorithms to real-world issues: supervised and unsupervised learning.
The advent of deep neural networks has revolutionized supervised learning, yielding accurate models in medicine and autonomous driving. Meanwhile, unsupervised learning, propelled by Generative adversarial networks (GANs), which fall under the umbrella of generative AI, has reshaped fashion and entertainment with synthetic data.
So, which is better? Should you choose one over the other or look for an alternate?
In this post, we’ll go through the difference between these fundamental approaches, highlighting their benefits and applications.
What is supervised learning
Supervised machine learning involves training a computer system with labeled input data. The computer then predicts output for unlabeled data.
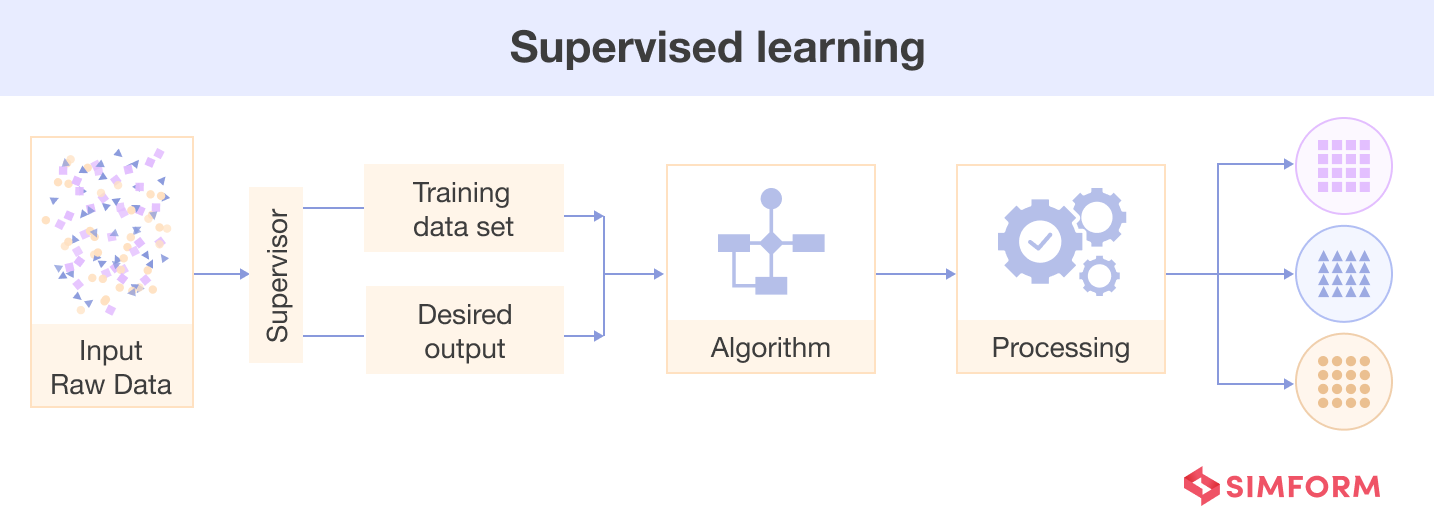
For example, in sentiment analysis, a model learns from labeled text samples gauging emotional polarity – positive and negative. This enables machines to detect sentiment through training with text-based emotion examples without human input.
What is unsupervised learning
Unsupervised learning is a machine learning model where AI learns patterns from unlabeled data without explicit guidance. It identifies inherent relationships, clusters, or patterns in data without predefined categories or target labels.
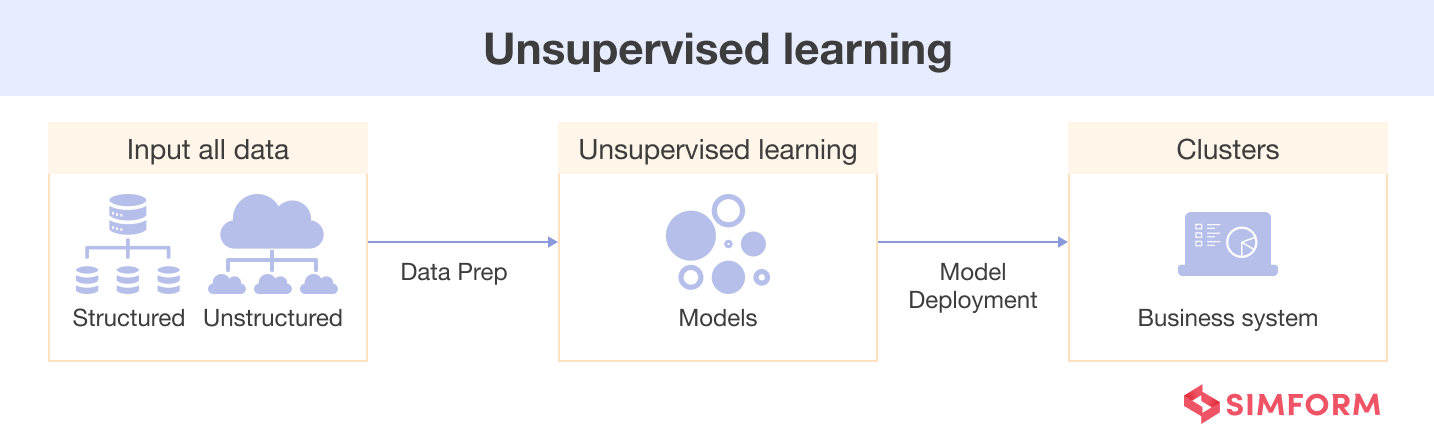 For example, in unsupervised learning, a model discovers the hidden patterns or similarities of the unlabeled fruits and classifies the new fruits that it has not seen before based on it.
For example, in unsupervised learning, a model discovers the hidden patterns or similarities of the unlabeled fruits and classifies the new fruits that it has not seen before based on it.
Advantages of supervised and unsupervised learning
Supervised learning:
- Produces precise, tailored results for specific tasks
- Excels at classification and regression problems
- Provides clear performance metrics for model evaluation
- Works well with labeled datasets
- Allows direct comparison between predicted and actual outcomes
Unsupervised learning:
Disadvantages of supervised and unsupervised learning
Supervised learning:
- Requires large amounts of labeled data
- Can be time-consuming and expensive to prepare training data
- May introduce human bias through the labeling process
- Struggles with unfamiliar or novel situations
- Can overfit to training data, leading to poor generalization
Unsupervised learning:
Supervised vs. Unsupervised Learning
|
Points of Difference |
Supervised Learning |
Unsupervised Learning |
|
What it is |
You train model using labeled input data alongside its corresponding paired labeled output data. |
You train the model to uncover concealed patterns within data that lack labels. |
|
Goal |
Predict target labels or outcomes |
Discover underlying patterns or structures in the data and apply those to new data for similar insights |
|
Performance Evaluation |
Can be evaluated using metrics like accuracy, precision, recall, etc. |
Evaluation is more complex and subjective, and often relies on domain knowledge |
|
Accuracy |
Pin-point accuracy |
Not much accurate |
|
Data Analysis |
Offline |
Real-time |
|
Techniques |
Linear regression, decision tree, neural network, logistic regression, etc. |
Dimensionality reduction, association, clustering, probability density, association rule learning, etc. |
|
Use Case |
Bioinformatics, predictive analytics, object recognition, customer sentiment analysis, etc. |
Organize computing clusters, astronomical data analysis, image and video analysis, social network analysis,etc. |
Let’s understand each of these differentiating factors:
1. Learning approach
Supervised learning comprehends the training dataset by iteratively generating predictions and fine-tuning them for accuracy. This approach deals with labeled training data where the system is familiar with output data patterns.
On the other hand, unsupervised learning models automatically discern underlying data patterns without any labels to guide them. Operating with unlabeled data, this algorithm derives output data from the collection of perceptions.
2. Feedback loop
Supervised learning operates over an iterative learning process with a feedback loop. It directly incorporates feedback on predictions, iteratively refines them, and improves its responses. This loop assists in adjusting settings and reducing forecast mistakes.
Conversely, unsupervised learning operates without explicit reinforcement and depends primarily on the underlying structure of the data.
3. Complexity
Supervised learning offers a straightforward approach, often computed using tools such as R or Python.
On the other hand, unsupervised learning tackles large unlabeled datasets to find the data’s hidden patterns. Training here is more difficult because of the predetermined output.
Moreover, both approaches grapple with concerns like overfitting and accuracy, though in different ways. Overfitting, a common pitfall in supervised learning, emerges when a model becomes overly tailored to training data, causing it to perform poorly on unseen data.
In unsupervised learning, the absence of specific output reduces traditional overfitting. However, models can still capture noise or anomalies, leading to inaccurate patterns.
Types of supervised learning and unsupervised learning
Supervised learning encompasses classification and regression techniques. Classification algorithms predict discrete categories, while regression algorithms estimate continuous values. Standard algorithms include decision trees, support vector machines, and neural networks.
Unsupervised learning focuses on clustering and dimensionality reduction. Clustering algorithms group similar data points, with k-means and hierarchical clustering being popular methods. Dimensionality reduction techniques like PCA and t-SNE simplify complex datasets.
Both approaches have distinct applications in data analysis, pattern recognition, and prediction tasks. Now, let’s understand the various supervised and unsupervised learning types with real-world examples.
Supervised and unsupervised learning examples
Supervised learning examples
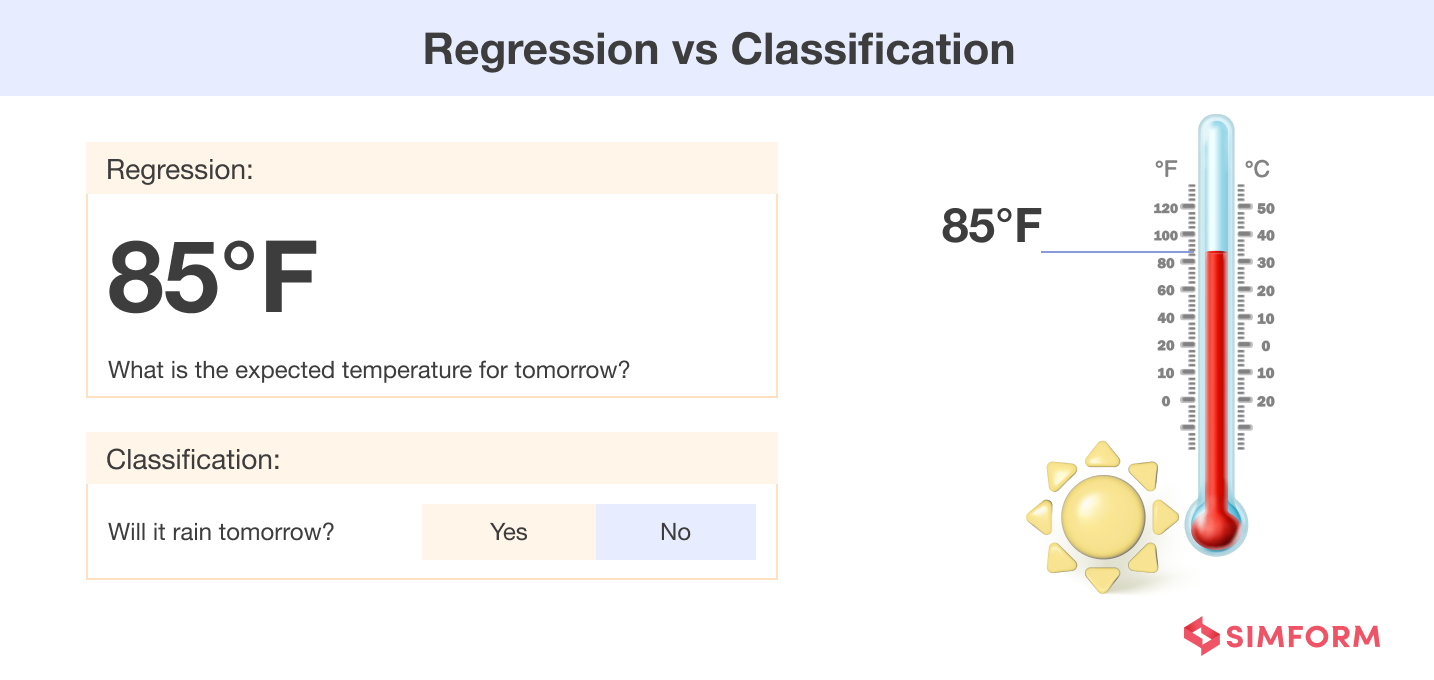
- Classification – Classification involves assigning new observations to specific categories based on training data. Here, an AI agent uses a given dataset to determine specific classes like “Yes” or “No,” “0” or “1,” or labels like “cat” or “dog.”
- Regression – Regression investigates the relationship between one or more independent variables and a dependent variable. It has diverse applications in predictive models, including financial forecasting, marketing optimization, health predictions, analyzing market trends, etc.
Unsupervised learning examples
- Clustering – Clustering groups unlabeled data by identifying patterns and similarities, revealing natural groupings. It uncovers trends, identifies outliers, and supports anomaly detection. The common methods in clustering are K-means Clustering and Gaussian Mixture Models (GMM).
- Association – Association is another unsupervised learning technique employing various principles to uncover connections between variables within a dataset. An example is market basket analysis or market segmentation and recommendation systems, resembling suggestions such as “Customers Who Purchased This Product Also Bought.” A prominent association method is the Apriori Algorithm.
- Dimensionality reduction – Dimensionality reduction is a method that trims the features in a dataset while keeping important information. This reduces the quantity of data inputs to a manageable level while maintaining data accuracy. Dimensionality reduction is frequently employed during data preprocessing, like when autoencoders eliminate visual noise to enhance image quality.
5. Goals
In the case of supervised learning, the main goal is cleared beforehand. Though, you need to clarify the goal for the unseen data.
On the contrary, in unsupervised learning, the aim is to understand patterns and trends within unlabeled data.
6. Drawbacks
Supervised learning models often demand significant time investment during the training phase, owing to the need for extensive labeled data for both input and output variables, which necessitates domain expertise.
Meanwhile, unsupervised learning approaches can yield results of varying accuracy, frequently requiring human intervention to validate the output variables and ensure their reliability.
7. Real-world use cases
Supervised learning has many uses and is one of the finest methods for obtaining accurate results. Here is a collection of well-known applications of supervised learning:
- Bioinformatics – It involves preserving the biological data of individuals, encompassing elements such as fingerprints, iris patterns, ocular features, and swabs.Contemporary smart devices can retain fingerprints, prompting authentication via either fingerprint or facial recognition whenever access is required.
- Object recognition – When you have a large dataset to teach your algorithm, you can use object recognition to identify a new instance. Raspberry Pi algorithms are an excellent example of object recognition.
- Spam detection – Supervised learning algorithms are pretty helpful in determining whether or not the email is spam. It recognizes and delivers a specific email to the relevant categorized or spam categories based on distinct keywords and content.
- Customer sentiment analysis – Understanding and analyzing customer comments, reviews, and interactions to discover their emotional tone, thoughts, and attitudes towards a product, service, or brand is what customer sentiment analysis is all about. This assists firms in gaining insight into customer happiness, identifying areas for development, and making educated decisions to improve the entire customer experience.
The unsupervised learning model provides a powerful means to analyze data, enabling businesses to uncover patterns within vast datasets. This approach has numerous real-time applications, such as:
- Organize computing clusters – The geographical regions of servers are established by clustering web requests received from a specific region across the globe. Subsequently, each local server will only contain data commonly generated by users from its corresponding region.
- Social network analysis – Social network analysis is done to prepare clusters of friends based on their connection frequency. This kind of analysis reveals the links between the users of similar social networking websites.
- Astronomical data analysis – Unsupervised learning facilitates astronomical data analysis by enabling the clustering of stars based on their properties. Also, it helps in identifying anomalies in celestial objects and extracting meaningful features from astronomical images.
- Image and video analysis – Performing image and video analysis manually is time-consuming, demanding significant human resources. However, unsupervised learning automatically detects objects in videos and images. This is beneficial in training specialized machine learning models utilized in self-driving cars, security cameras, and medical imaging.
When to use: Supervised vs. Unsupervised learning
You can use supervised learning when you:
- Have a clear-cut problem and are aware of potential outcomes
- Possess limited labeled training data but have a substantial amount of unlabeled data
- Are dealing with problems that involve predicting a particular output variable, like in classification or regression tasks
- Aim to cut down the cost of labeling data
Conversely, you can use unsupervised learning when you:
- Lack labeled data or a specific task to accomplish, but wish to explore data and discover concealed patterns or clusters
- Want to reduce the dimensionality of your data or conduct feature extraction
- Have expertise in data interpretation and analysis
- Need to uncover hidden patterns or structures within data
Can we use supervised and unsupervised learning together?
Yes, you can use both supervised learning and unsupervised learning jointly with semi supervised learning, which is a separate machine learning category in itself.
What is semi-supervised learning?
Semi supervised learning is beneficial when labeling a dataset is difficult. If you have a limited number of labeled training data but a large amount of unlabeled data, combining supervised and unsupervised learning methods can considerably enhance accuracy and efficiency.
ChatGPT is a timely example that incorporates both supervised and unsupervised learning techniques. If you combine human feedback to it, it becomes Reinforcement Learning with Human Feedback (RLHF), which is the key to ChatGPT’s breakthrough performance.
Parting words
In the world of AI and ML, the debate on supervised vs unsupervised learning has been ongoing. No algorithm or approach is superior. It all comes down to the use case.
For instance, if you’re building a conversational AI, the power lies in combining supervised learning and unsupervised learning with human feedback.
Hence, prior to deciding,
- Assess your input data
- Define your objectives
- Scrutinize algorithm choices
Most importantly, choose the right development partner.
FAQs:
Ans: The main difference between supervised and unsupervised machine learning is that supervised learning uses labeled training data, while unsupervised learning works with unlabeled data. In supervised learning, the algorithm learns to map inputs to known outputs. Unsupervised learning finds patterns or structures in data without predefined labels.
Ans: LLMs typically use a combination of supervised and unsupervised techniques. The initial training is often unsupervised, using vast amounts of unlabeled text data. Fine-tuning and alignment may involve supervised learning with labeled data. Overall, LLMs lean more towards unsupervised learning in their core training approach.
Ans: Supervised learning involves training a model on a labeled dataset where the desired output is known. The algorithm learns to map inputs to correct outputs, minimizing the difference between its predictions and the proper labels.
Ans: Unsupervised learning focuses on discovering hidden patterns or structures in unlabeled data. The algorithm explores the data to find inherent groupings, relationships, or representations without predefined output labels.
Ans: Use supervised learning when:
- You have an explicit target variable or outcome to predict
- Labeled training data is available
- The goal is to make specific predictions or classifications
Use unsupervised learning when:
- You want to explore data structure without predefined labels
- The goal is to discover patterns, groups, or relationships
- Labeled data is unavailable or expensive to obtain
Ans: Clustering is an unsupervised learning technique. It groups similar data points without predefined labels. The algorithm discovers inherent structures in the data based on similarities or distances between points.
Ans: Deep learning can be both supervised and unsupervised, depending on the specific architecture and task:
- Supervised deep learning uses labeled data to train neural networks for tasks like image classification or speech recognition.
- Unsupervised deep learning, such as autoencoders or generative adversarial networks, learns from unlabeled data to discover patterns or generate new samples.
Ans: Regression is a supervised learning method that predicts continuous numerical values based on input features. It uses labeled training data to learn the relationship between inputs and outputs.
