Pixis: A codeless AI infrastructure to nitro-boost your marketing.
Category: AI-powered solutions
Services: DevOps, Cloud Architecture Design and Review, Managed Engineering Teams.
Category: AI-powered solutions
Services: DevOps, Cloud Architecture Design and Review, Managed Engineering Teams.

The client was facing various challenges with their infrastructure, including a lack of containerization, no standardized process for cost tracking and infrastructure management, no DevOps practices, and high costs. They wanted to develop a new infrastructure with continuous deployment and cost-effectiveness in mind.
Additionally, there were issues with scaling and background tasks, and some services still needed to be migrated to the new infrastructure. The overall goal was to improve the efficiency and cost-effectiveness of the client’s infrastructure while ensuring scalability and reliability.
Simform’s team used AWS EKS for containerization and to simplify deployment, management, and scaling of services. With EKS, each product could have its own EKS cluster, which would be more cost-effective and easier to manage than cluttered infrastructure.
The Simform team has set up new infrastructure with infrastructure as code practice using terraform. We have implemented the DevOps and SDLC practices on infrastructure creation such as versioning,PR review, CI/CD etc for infrastructure code.
Simform used AWS EKS to optimize costs, as it offers more cost-effective management of infrastructure. We also used AWS S3 in the solution for storing static content, ML models, and data sets, and using tagging policies to monitor costs.
Simform proposed migrating all services to AWS EKS, including the legacy sync and SAAS Chrome extension services.
Simform proposed using AWS EKS to improve the scalability and reliability of the client’s infrastructure. Simform suggested que-based scaling solutions for background tasks and Redis for caching.
EKS managed nodegroups, k8s taints, and affinity can help ensure that each service only uses the necessary resources. For example, certain ML services require CPU and GPU-intensive machines only when generating recommendations or adding text to videos. To implement queue-based scaling on EKS, we suggested the client to use KEDA. When a new message is queued, a new pod will be launched, and the EKS cluster autoscaler will spin up and down nodes based on the number of queued messages.
Our team has set up a scalable and fault-tolerant api endpoint with the help of NLB and Nginx ingress controller. This ensured that the services could handle large workloads and traffic spikes without performance issues.
Our team has built a CI-CD pipeline for each microservice running on EKS cluster.
Finally, we set up monitoring and alerting logging using Grafana, Prometheus, and cloudwatch, which helped the team in monitoring and resolving issues proactively.
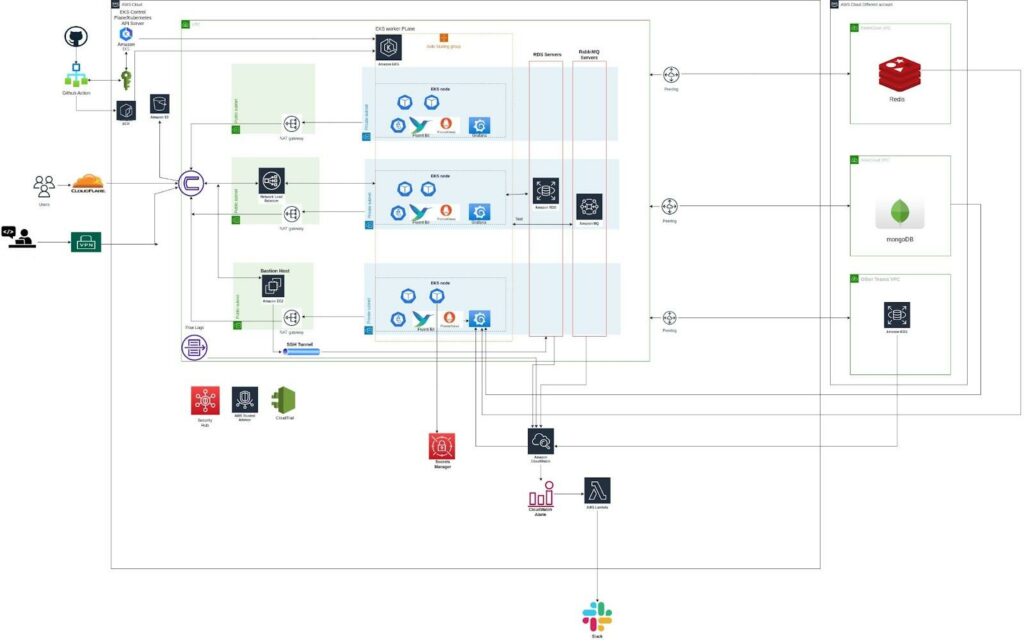
Using these monitoring tools, Simform can proactively identify and resolve issues before they impact end-users, ensuring a high level of performance and availability for the client’s microservices-based architecture.