Building interactive serverless applications is easier than ever with AWS Lambda. It offers remarkable features such as pay-as-you-go pricing and auto-scaling since AWS manages the required resources. But when it comes to performance, Lambda cold starts can be a huge problem, especially for latency-critical applications.
AWS Lambda’s provisioned concurrency is one such feature that helps you reduce latency and allows greater control over the performance of your serverless applications. This proves to be a major benefit of provisioned concurrency in the provisioned vs reserved concurrency battle. By understanding the dynamics of serverless provisioned concurrency, you can unlock strategies to mitigate cold starts effectively.
What is Lambda provisioned concurrency?
Concurrency in AWS Lambda is the number of requests a function can handle at any given time. All AWS accounts have a default concurrency limit of 1000 per region.
For an initial burst in your function’s traffic, the cumulative concurrency in a region can reach between 500 and 3000 (varying per region). And after the initial burst, it can scale by 500 additional instances per minute. But when a function reaches its maximum concurrency or when requests come in faster than a function can scale, the additional requests are throttled as we can see below.
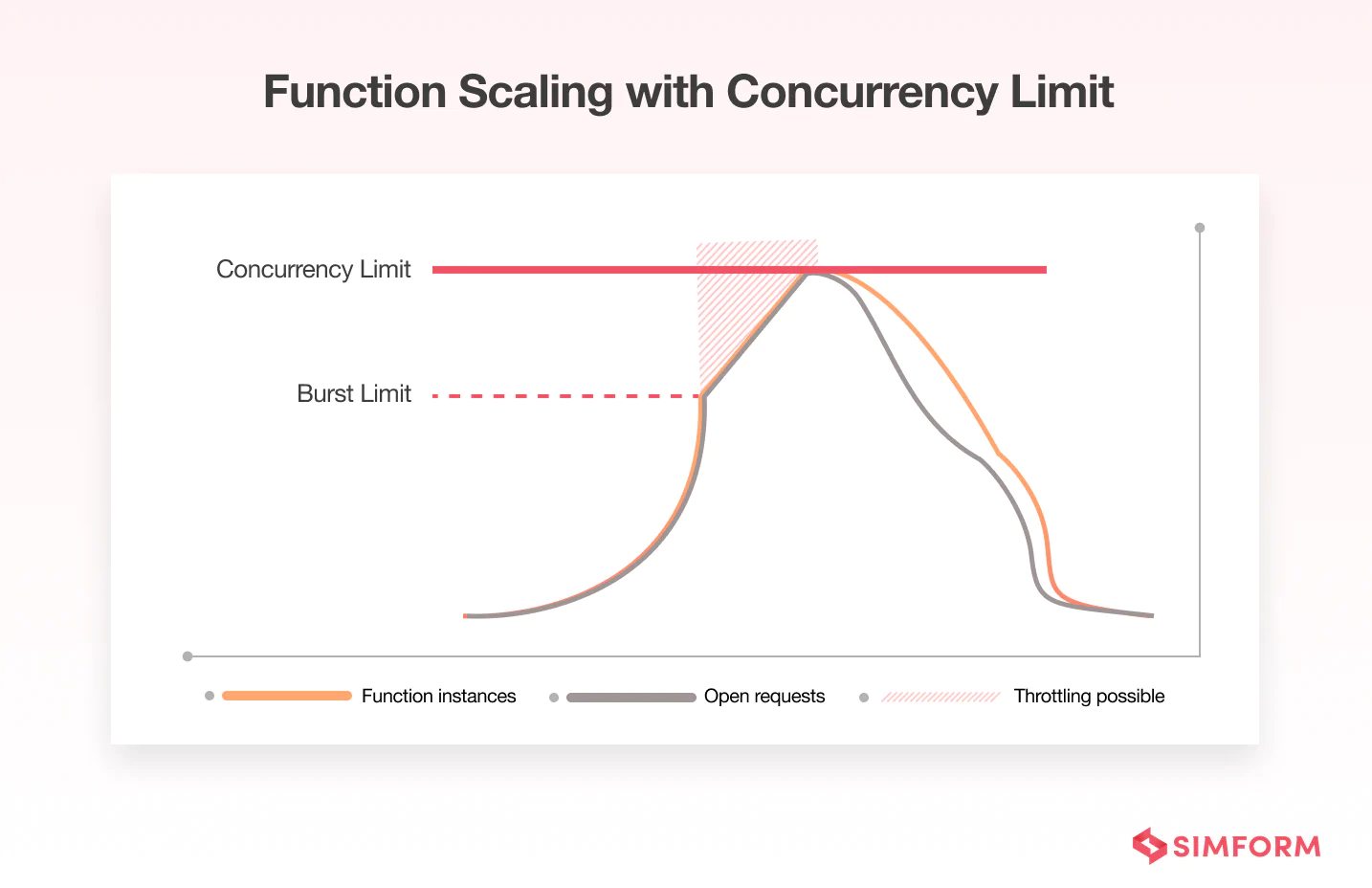
However, there is a solution to enable your serverless functions to scale without fluctuating the latency– AWS Lambda provisioned concurrency. Consider the same example but with provisioned concurrency processing a traffic spike.
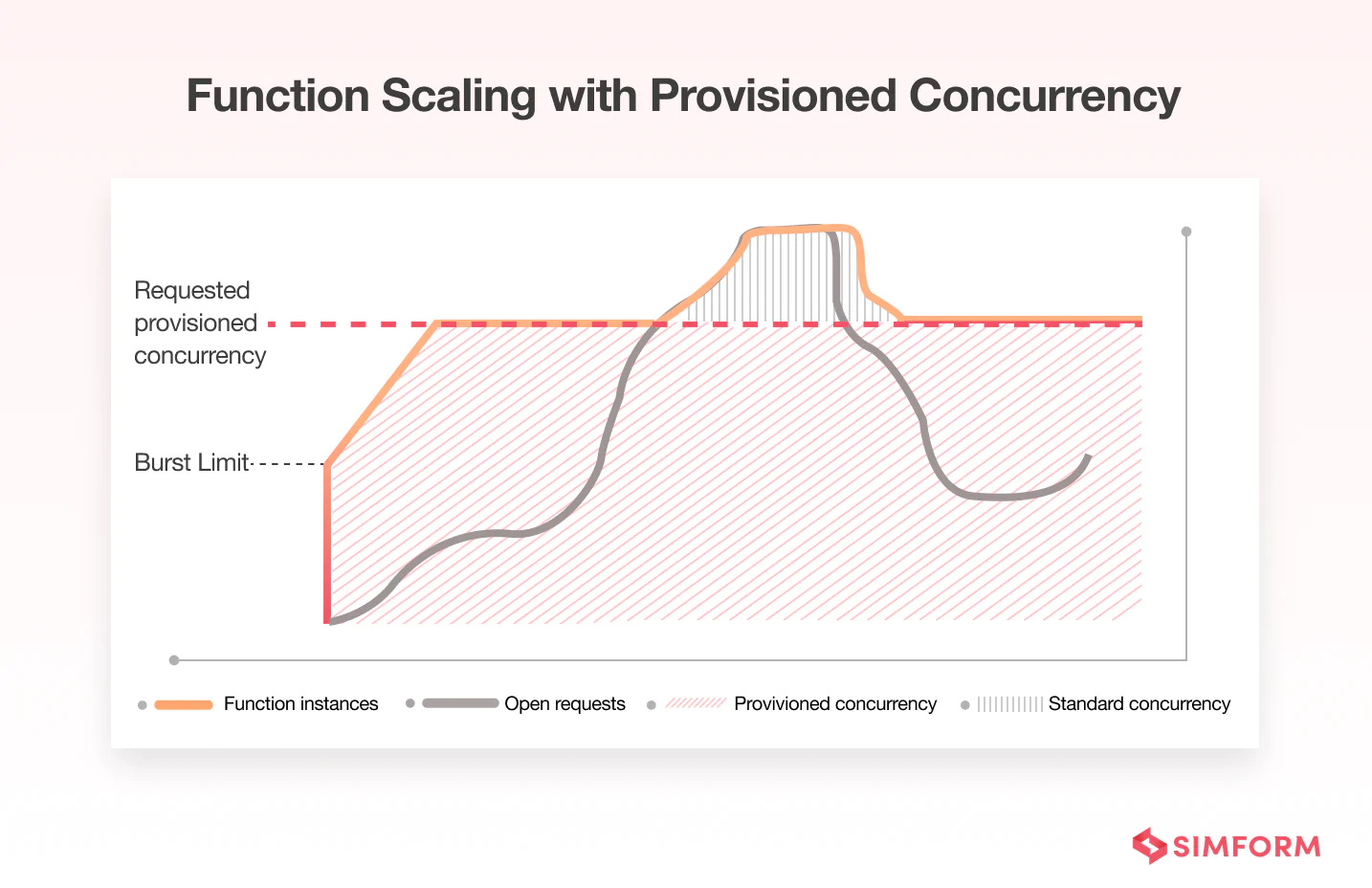
Configuring provisioned concurrency for your Lambda functions solves two issues:
I. If the expected traffic arrives faster than the default burst capacity, your function can meet the demand due to provisioned concurrency. Thus, it avoids throttling.
II. It solves the typical problem of Lambda cold starts that occur when a function is initially invoked or due to default scaling. So if you have latency-sensitive workloads, they perform with zero or very low latency.
Features of Lambda Provisioned Concurrency
AWS Lambda Provisioned Concurrency offers features to enhance scalability for serverless applications. Here are the major features of Lambda provisioned concurrency:
- A reliable way to keep functions ready to serve sudden traffic bursts and significant scaling events
- Pre-prepare containers and execution environments for your functions
- Reduces start or response time to <100ms
- Gives more control over the performance of serverless applications
- No custom code changes required for its configuration
- Incurs additional charges
- Works with any trigger, such as WebSockets APIs, GraphQL resolvers, or IoT Rules
- Supports scheduling with Application Auto Scaling
- Simple to configure the lambda provisioned concurrency via AWS CloudFormation, AWS Lambda Console, AWS CLI, AWS Lambda API or AWS SDK
- Broad support for partner tools, including Serverless Framework and Terraform, or viewing metrics with Datadog, Epsagon, Lumigo, New Relic, SignalFx, SumoLogic, and Thundra
Lastly, you must note that the provisioned concurrency limit comes from your regional limit. So if you configure it on multiple function aliases/versions or a specific version, it counts towards the regional concurrency limit. In case the function is also configured with reserved concurrency, provisioned concurrency cannot exceed its reserved limit.
How provisioned concurrency optimizes performance for Lambda-based applications?
The problem of cold starts: When a Lambda function is invoked, the first invocation is routed to a new execution environment for processing the request. The function remains available to handle concurrent incoming requests. And when the requests subside, the instances are shut down after being idle for some time so that you don’t incur charges while waiting for other requests. Hence, new execution environments are spun up from scratch whenever you need to process more concurrent requests or update a function.
Now, the creation of instances involves installing the function code and initializing the runtime, which can introduce latency, referred to as cold starts.
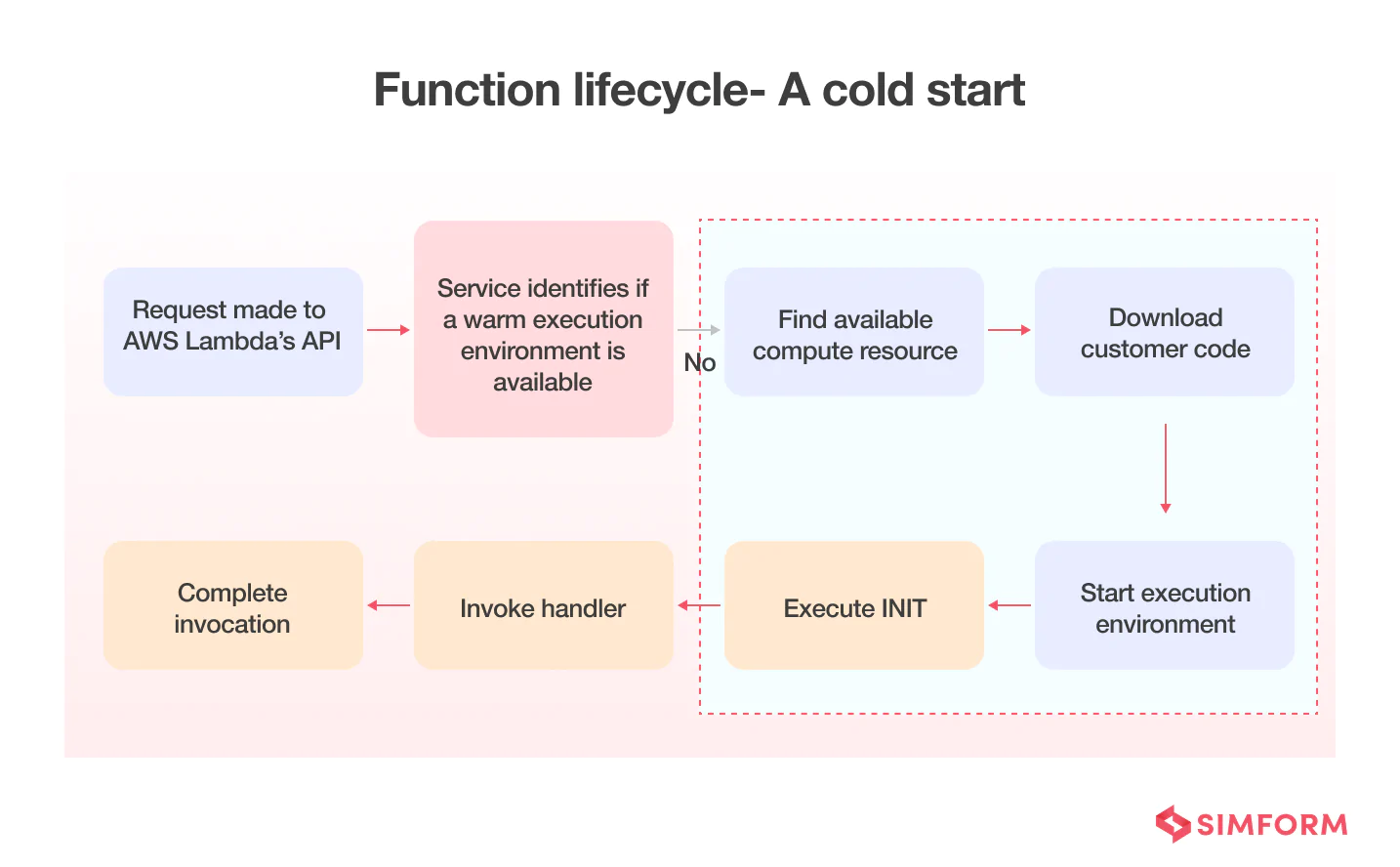
But when provisioned concurrency is enabled, Lambda service initializes the requested number of execution environments and keeps them warm so they are hyper-ready to respond in double-digit milliseconds. Thus, it helps avoid cold starts and gives a much more stable user experience.
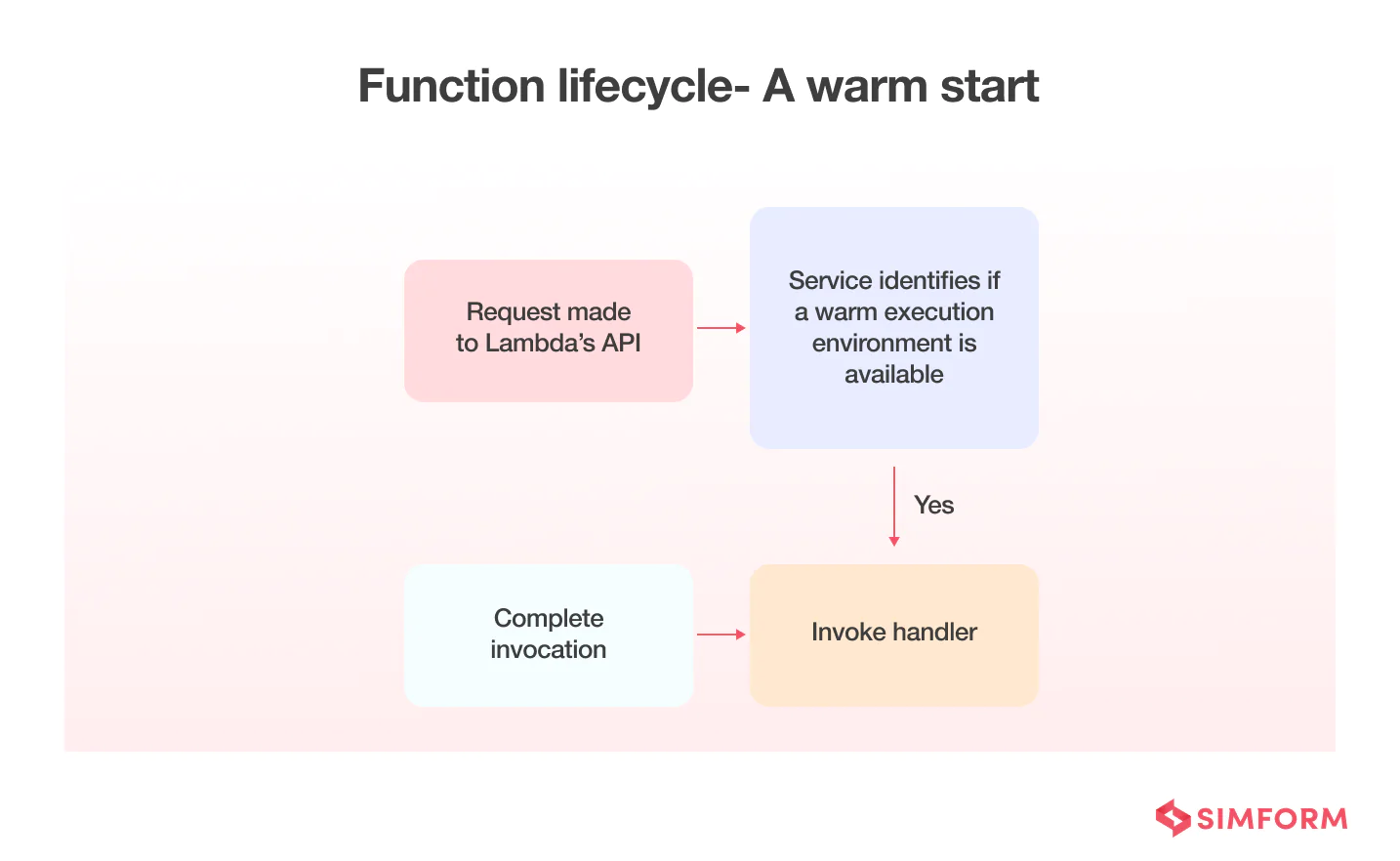
- An example of beating cold starts with provisioned concurrency
Let’s say you are building a serverless on-demand food delivery app. And you have integrated the online payments workflow using AWS Lambda functions, API Gateway, DynamoDB, and S3.
The app users may experience cold starts while making payments during peak hours at lunch and dinner. Because the specific function managing the payments will experience a flood of requests during these hours. And it will have to spin up new instances to serve the initial requests, introducing cold starts and latency.
But if instances are ready to serve requests before they occur, it will reduce latency and avoid cold starts. Thus, provisioned concurrency improves its performance. Simform’s cloud engineers have improved the performance of hundreds of applications using provisioned concurrency. We used provisioned concurrency to eliminate the issue of cold starts in Lambda applications, proving that it is arguably a better choice.
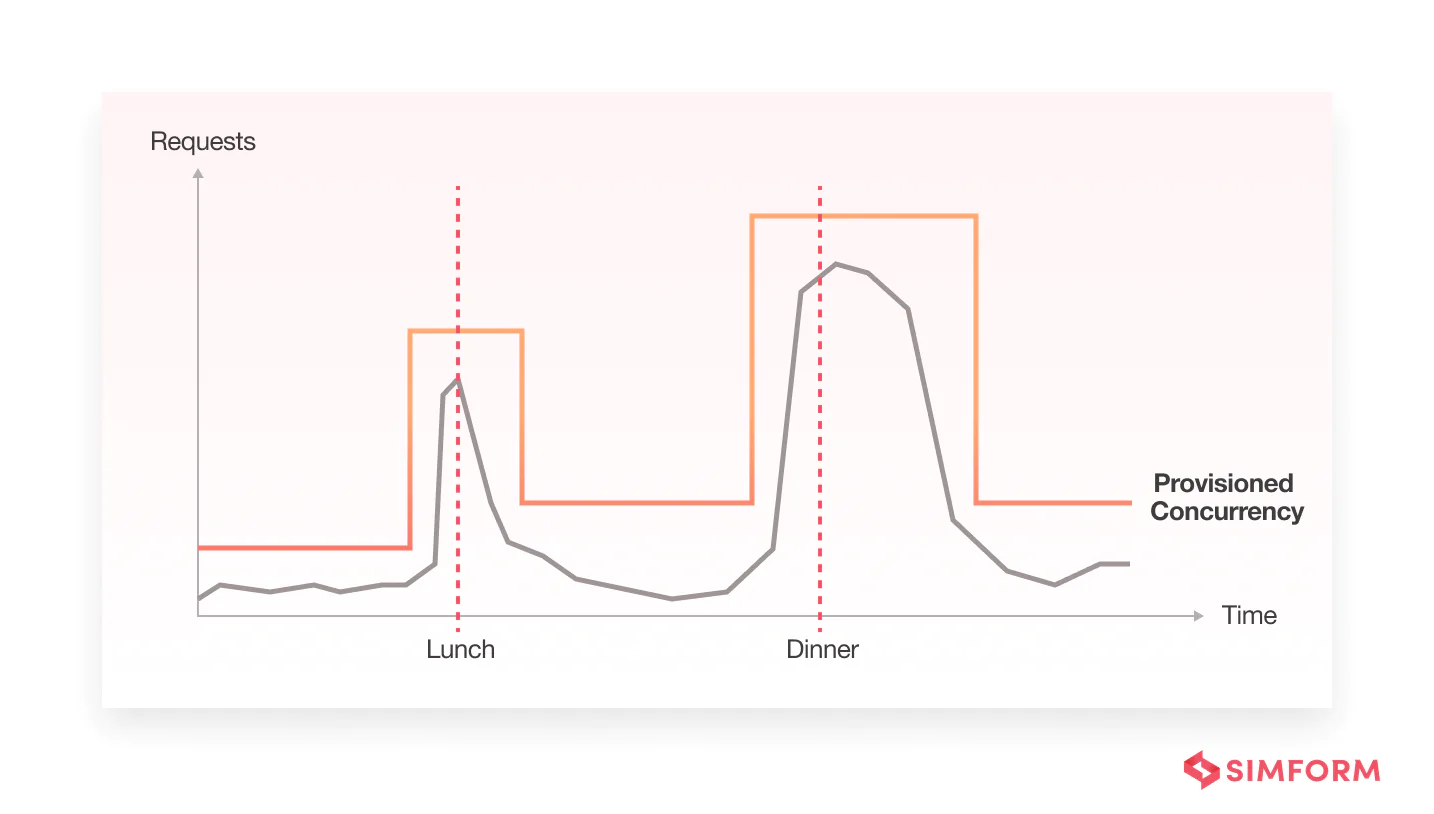
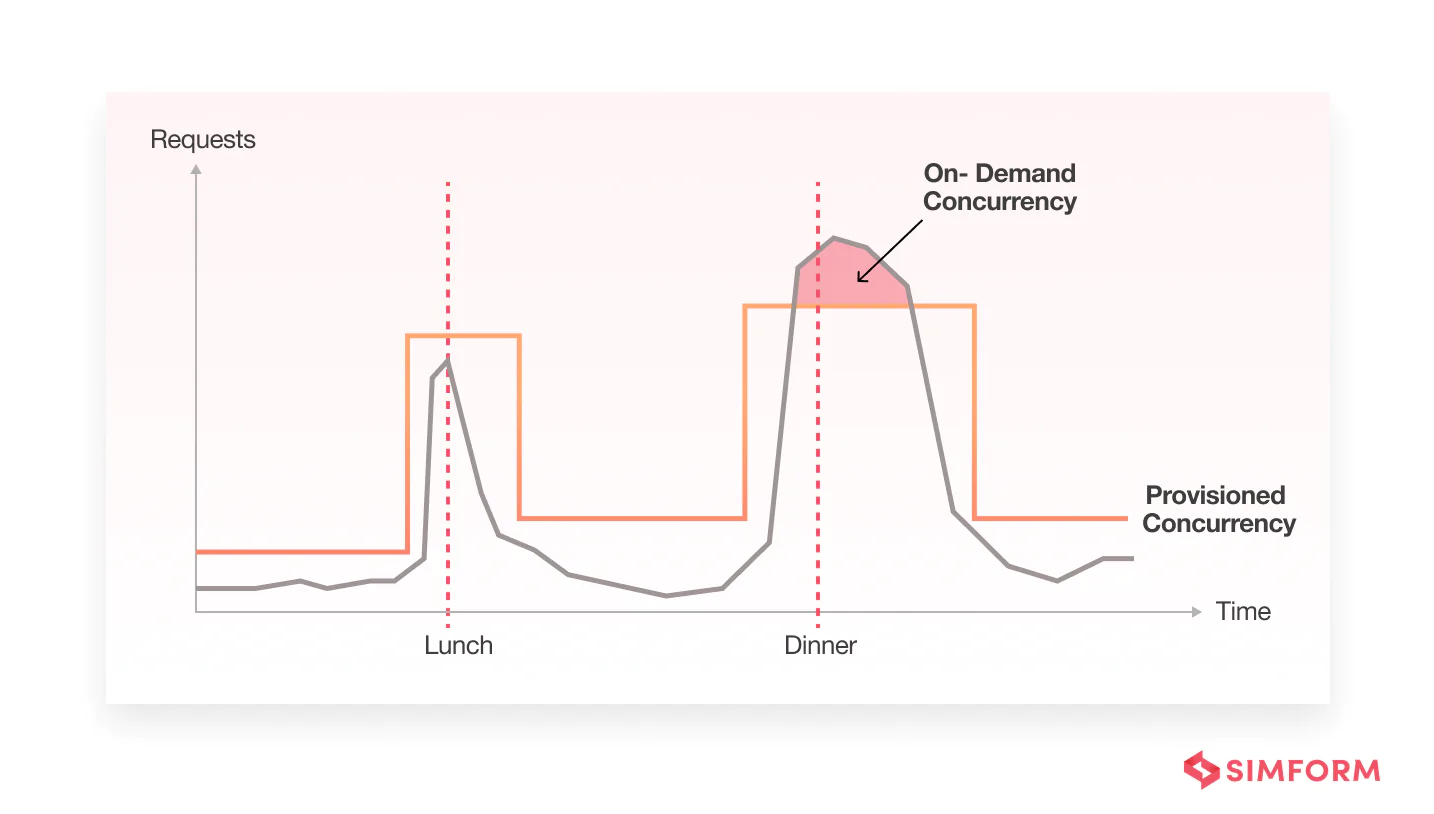
Moreover, when more requests come in than provisioned concurrency can handle, it can simply spill over to on-demand scaling. Of course, there will still be cold starts for the spillover invocations, but they will be fewer and less frequent if you have configured enough provisioned concurrency.
How to Monitor Provisioned Concurrency?
Monitoring provisioned concurrency in AWS Lambda is a critical aspect of optimizing the performance of your serverless applications. Leveraging CloudWatch metrics provides invaluable insights into the behavior of your Lambda functions, enabling you to make data-driven decisions and ensure efficient resource utilization.
Provisioned Concurrent Executions
One key metric to focus on is the provisioned concurrent executions. This metric gives you a real-time view of the current concurrent executions that are utilizing provisioned concurrency. By regularly monitoring this metric, you can gain a deeper understanding of the workload on your functions and make adjustments as needed to maintain optimal performance.
Provisioned Concurrency Utilization
The provisioned concurrency utilization metric is equally important, offering insights into the fraction of provisioned concurrency that is actively in use. This information is invaluable for assessing the efficiency of your allocated resources, allowing you to fine-tune your AWS provisioned concurrency settings for maximum efficiency.
Provisioned Concurrency Invocations
Tracking the provisioned concurrency invocations metric provides visibility into the number of invocations specifically using provisioned concurrency. This metric is essential for assessing how frequently your reserved capacity is being utilized. Understanding the utilization patterns helps you make informed decisions about adjusting your provisioned concurrency levels based on actual demand.
Provisioned Concurrency Spillover Invocations
In addition, the provisioned concurrency spillover invocations metric is crucial for identifying instances where the number of invocations exceeds the provisioned concurrency limit. This insight helps you pinpoint potential capacity issues and allows for timely adjustments to avoid performance degradation during periods of high demand.
Managing AWS Lambda concurrency limits is essential for operating serverless Lambda functions efficiently. Regularly reviewing concurrency metrics helps you stay ahead of bottlenecks.
With AWS provisioned concurrency for Lambda, you can allocate a specific number of Lambda concurrent executions. This ensures your functions have the necessary resources available when demand spikes, preventing delays in processing and maintaining performance.
Considering Lambda concurrent execution within the broader framework of AWS services, optimizing these executions is fundamental to achieving cost efficiency and operational excellence. The CloudWatch metrics discussed earlier serve as invaluable tools in this optimization journey, providing actionable insights for continuous improvement.
Regularly monitoring key concurrency metrics is essential for effective management of AWS Lambda reserved concurrency limits. This proactive approach ensures that your serverless applications consistently deliver optimal performance, scalability, and cost-effectiveness.
Auto Scaling Lambda provisioned concurrency
With the activation of provisioned concurrency, the question of additional costs arises. But what if you can save costs while using provisioned concurrency? It is where Autoscaling comes to your aid. You can configure Application Auto Scaling to manage provisioned concurrency of your Lambda functions and optimize its usage. Simply put, auto scaling lets you increase the number of warm instances just for a particular amount of time required for cost efficiency.
For example, as discussed in the food delivery app example above, it can get more orders during lunch and dinner hours. So, you can autoscale provisioned concurrency to keep up with the traffic economically while giving a stable user experience. Auto scaling can be done with two methods, as described below.
Scheduled scaling
It can be used when you have predictable workloads, such as when you can anticipate peak traffic or spikes in traffic. For instance, let’s say you have an application that caters to a company where employees work from 9 to 5. The number of requests will be higher during this period.
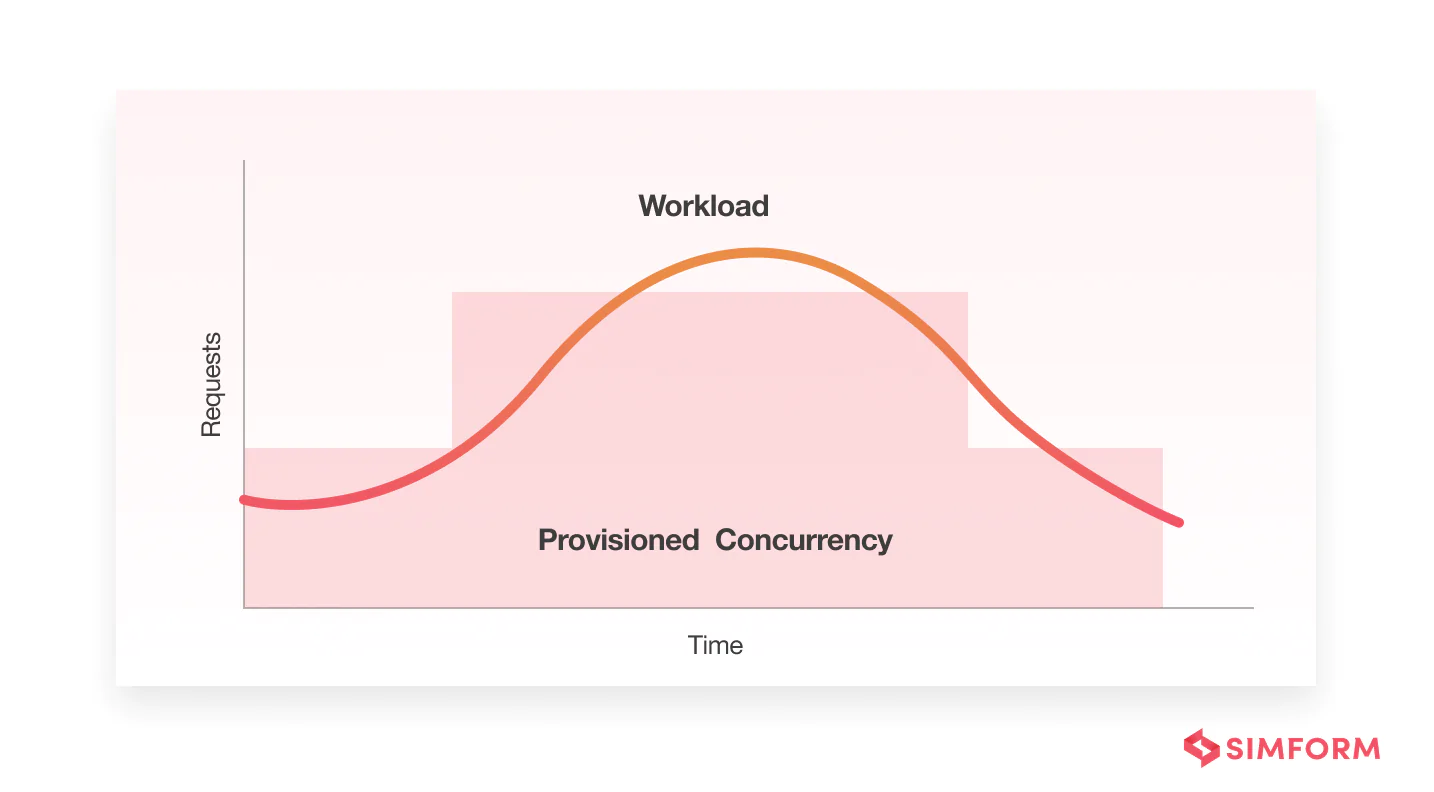
- Save money by scheduling provisioned instances for a fixed amount of time instead of keeping it active all the time
- Save time, cost, and efforts by scheduling provisioned concurrency automatically
Utilization-based scaling
You can use utilization-based scaling to increase provisioned concurrency based on the need at runtime. This method, relying on measured utilization metrics, proves particularly valuable when request rates are unpredictable. The Application Auto Scaling API helps you register a scaling target and create an autoscaling policy seamlessly.
Configuring these parameters is flexible, allowing you to do so through the AWS Management Console for a user-friendly experience. This adaptive scaling strategy is especially beneficial in scenarios where AWS Lambda rate limits may pose challenges.
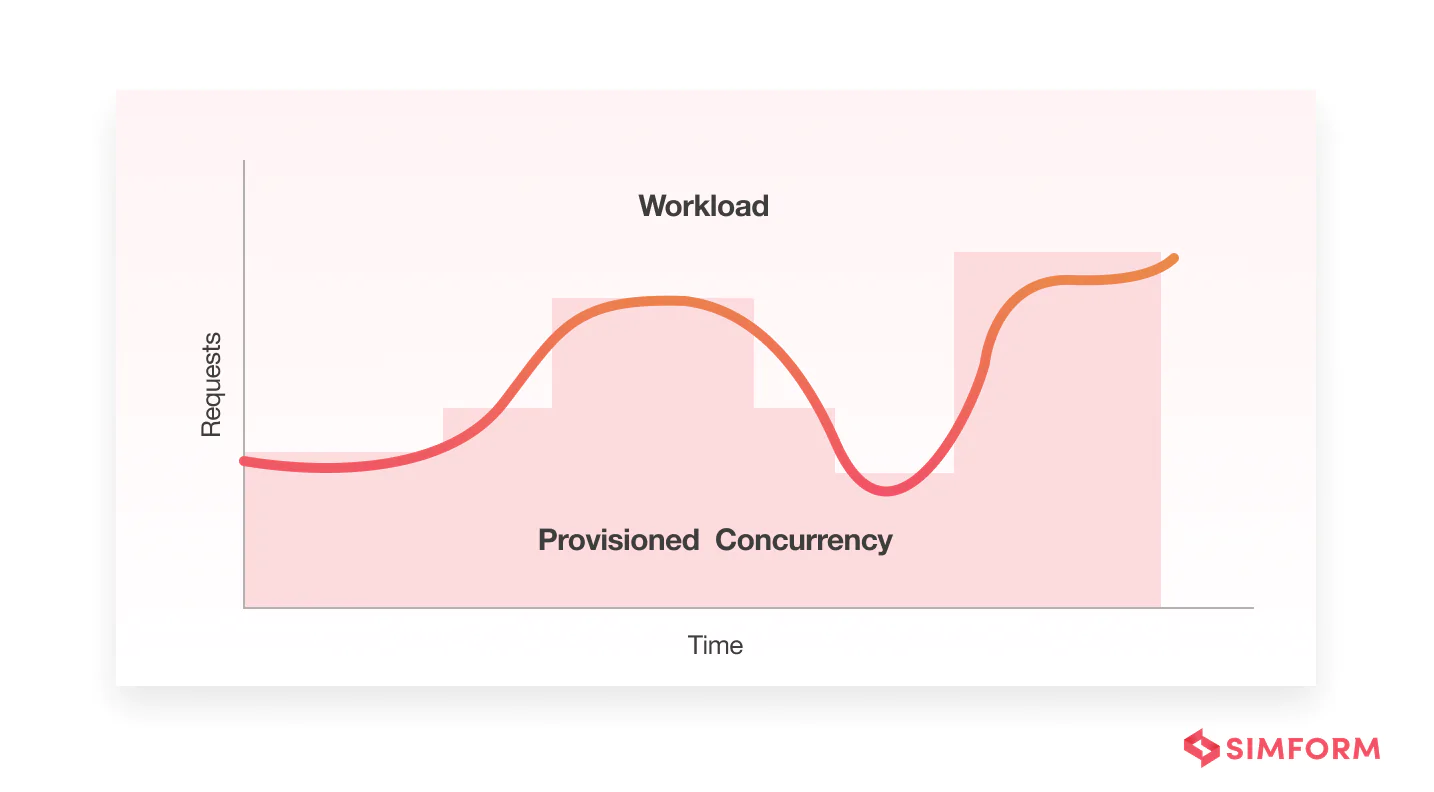
- Save time spent on manual provisioned concurrency settings
- Save costs by automatically fitting provisioned concurrency according to the workloads when they are unpredictable
AWS Lambda provisioned concurrency pricing
AWS charges additional costs for provisioned concurrency in addition to the regular Lambda costs. However, it has a slightly different pricing model.
You only pay for the concurrency limit you configure and the period of time you configure it. When the provisioned concurrency is enabled and executed, you also pay for the requests and the execution duration as given below. If a function’s concurrent executions exceed the configured limit, you will pay for the excess function execution as per Lambda pricing. To know more, you can refer to the AWS documentation here.
Moreover, Provisioned concurrency is calculated from the time you enable it on your functions until it terminates, rounded up to the nearest five minutes. The price also depends on the amount of memory you allocate to your functions and the amount of concurrency you configure on it.
For instance, on-demand concurrency charges are as given below:
- Invocation duration: $0.06 per GB-hour, 100ms round-up
- Requests: $0.20 per 1M requests
And provisioned concurrency has slightly lower costs but introduces an extra uptime component:
- Invocation duration: $0.035 per GB-hour, 100ms round-up
- Requests: $0.20 per 1M requests
- Memory: $0.015 per GB-hour, 5 minutes round-up
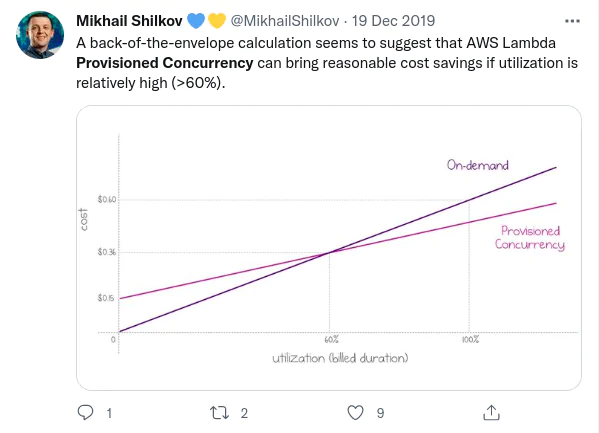
Let’s take a pricing example to know how much cost difference provisioned concurrency can make. If you configure one Provisioned Concurrency on a function with 1GB memory, you pay $0.015 per hour for it (rounded up to the next five minutes), even if there are no invocations. And if you configure ten Provisioned Concurrency for the same function, you’ll pay $0.15 per hour for them.
Now, upon invocation it will cost $0.035 + $0.015 = $0.05 per GB-hour for a fully utilized concurrency execution. It is $0.01 (16%) cheaper than on-demand concurrency. However, it might not be the case for all scenarios. If your application is looking to serve a large and growing capacity of requests, the billing for on-demand scaling may increase respectively. And provisioned concurrency can save overall costs when heavily utilized, while also boosting the performance of Lambda apps.
Lambda provisioned concurrency vs. reserved concurrency
Provisioned concurrency is not the only concurrency control provided by AWS. While provisioned concurrency initializes a certain number of instances, reserved concurrency guarantees a maximum number of concurrent instances for invocations.
Below is a comparison between provisioned concurrency and reserved concurrency offered by Lambda.
| Provisioned Concurrency | Reserved Concurrency |
| Initializes a requested number of instances, so they are prepared to respond immediately to a function’s invocations | Guarantees a maximum number of concurrent instances for a function when invoked |
| Incurs additional charges | No additional charges |
| Benefits: Helps avoid throttling of requests and reduce cold starts | Benefits: Other functions cannot prevent a function from scaling & a function cannot scale out of control, so no overloading of downstream resources |
However note that reserved concurrency does not help avoid cold starts. To avoid cold starts, you have to go with provisioned concurrency.
Use cases for Lambda provisioned concurrency
There are numerous AWS Lambda use cases that involve traffic bursts. It is where provisioned concurrency can prove to be useful. To sum up, let’s take a quick look at the ideal use cases for provisioned concurrency in Lambda.
Provisioned concurrency enables Lambda functions to run with predictable start-up times and low or zero latency while scaling. Thus, it can be ideal for various Lambda-based applications, including web apps, mobile apps, gaming apps, or any service that is part of a complex transaction. And since it gives developers better control over performance, it can also be implemented for applications that require low latency, such as interactive services, web and mobile backends, latency-sensitive microservices, or synchronous APIs.
Moreover, when combined with auto-scaling, this approach enables cost-efficient, scalable, and high-performing serverless services. If you’re looking to implement this solution and need expert guidance, talk to Simform’s AWS-certified team. We bring deep AWS expertise to help organizations build innovative tech solutions using the right services for their goals.