Large language models (LLMs) are remarkable tools for processing vast data and generating human-like text. They are already used for virtual AI assistance, image annotation, natural language processing, and more. However, LLMs commonly cause hallucinations. These subtle errors can have serious consequences if undetected.
A good example of these fabrications can be found in our interaction with ChatGPT. When asked for Elon Musk’s quotes on India, the bot came up with one that Elon shared during his interview with Mathias Döpfner. While the interview did take place in December 2020, it didn’t feature this quote
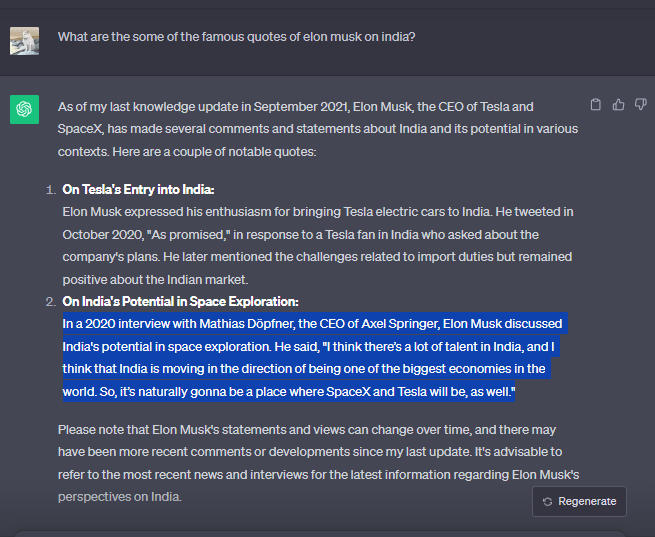
AI hallucinations can spread misinformation, leading to misinformed decision-making. It’s important to understand what causes generative artificial intelligence models to hallucinate and how to detect these fabrications to mitigate their risks. And this blog post will help you do just that.
Let’s begin with understanding what exactly LLM hallucination means.
What is an LLM hallucination?
LLM hallucinations are instances in which an AI model confidently generates inaccurate outputs that aren’t justified by its training data. It can take various forms, from subtle mistakes to glaring false results.

AI hallucination can easily be missed by users, but understanding its various types can help identify the fabrications.
Types of LLM hallucination
According to “A Survey on Hallucination in Large Language Models” research paper, there are three types of LLM hallucination.
| Type of hallucination | Meaning | Example input | Output |
| Input-conflicting hallucination | LLMs generate content that deviates from the source input provided by users. | A product manager provides the LLM with a customer interview transcript and asks it to summarize key user needs. | The LLM generates a summary that includes user needs not mentioned in the transcript. |
| Context-conflicting hallucination | LLMs generate content that conflicts with previously generated information by itself. | A product manager asks the LLM for the top two user complaints about their app. They then ask about the issues impacting user retention. | The LLM mentions slow loading times and unintuitive menus as top user complaints. For the second question, it mentions crashes and lack of notifications. |
| Fact-conflicting hallucination | LLM generates text that contradicts established facts and knowledge about the world. | A CEO asks the LLM, “What is the market share of competitor Z in the autonomous vehicle industry?” | The LLM generates a detailed percentage that has no factual basis, as this data about the competitor is not publicly available. |
In a recent paper named “How Language Model Hallucinations Can Snowball,” authors found many questions that can cause GPT-4 and ChatGPT to hallucinate so badly that in a separate chat session, they can point out that what they previously said was factually incorrect.
Sparks of stupidity?
We've found a wide array of questions that lead GPT-4 & ChatGPT to hallucinate so badly, to where in a separate chat session they can point out that what they previously said was incorrect.https://t.co/ptim93wYov@zhang_muru et al🧵⬇️ pic.twitter.com/K7S26zqFBA
— Ofir Press (@OfirPress) May 22, 2023
Let’s check out some more real-world examples of LLM hallucination that the tech industry has witnessed recently.
AI hallucination instances that made headlines
Prominent LLMs like Bard, Galactica, and ChatGPT show how even state-of-the-art language models are susceptible to generating misinformation through hallucination.
- Bard’s infamous factual error
In February 2023, Google launched its large language model, Bard, to compete with ChatGPT. However, Bard’s launch made all the wrong headlines because of a major factual error in one of its first responses. When asked, “What new discoveries from the James Webb Space Telescope can I tell my 9-year-old about?” Bard claimed that the telescope had snapped the first-ever images of a planet outside our solar system. However, the claim was actually incorrect. According to NASA’s records, we got our first glimpse of an exoplanet in 2004, before the James Webb Space Telescope took off in 2021.
- Galactica’s made-up attribution
Another notable incident happened when Meta showcased Galactica, a language model tailored for scientific researchers and students. When asked to draft a paper on avatar creation, this model referred to a made-up paper on the topic and attributed it to a real author in a relevant field.
While these LLM hallucinations were easily caught by the respective users, it’s not always the case. It’s important to understand how to detect hallucinations in LLMs to avoid misinformed decision-making.
How to detect LLM hallucinations
Detecting hallucinations in large language models can be a challenging but important task, especially in applications where accuracy and reliability are crucial. Here are some methods and approaches to detect hallucination in LLM-generated text:
- Fact Verification: Cross-reference the information generated by the LLM with external data sources, trusted references or databases to verify the accuracy of facts presented in the text. If the information contradicts established facts, it may be a sign of hallucination.
- Contextual Understanding: Analyze the context of the generated text to determine if it aligns with your query or the conversation history. Hallucinatory responses may diverge significantly from the additional context or your previous inputs.
- Adversarial Testing: Adversarial testing involves crafting input prompts designed to challenge the model to generate hallucinated text. By creating adversarial examples and comparing the output to human-curated responses, hallucination patterns can be identified, leading to improved detection mechanisms.
- Consistency Analysis: Check for consistency within the generated text. Hallucinatory responses may contain contradictions or inconsistencies. You can use automated tools to identify logical inconsistencies within the text.
- Chain of Thought Prompting: Chain of thought prompting involves asking the LLM to explain its logical reasoning step-by-step behind generated text. This allows tracing the reasoning chain to identify contradictory logic or factual gaps indicating hallucination risks.
Many organizations are also working towards identifying hallucinated content at the token level. This method assesses the likelihood of each token in the output being a hallucination and incorporates unsupervised learning components for training hallucination detectors.
Another notable framework, called ExHalder, was presented by Google to tackle headline hallucination detection. ExHalder adapts knowledge from public natural language inference datasets into the news domain and uses it to generate natural language explanations for hallucination detection results.
By combining these methods and considering token-level analysis, organizations can enhance their ability to detect and mitigate hallucinations in LLM-generated content. However, the best solutions can only be built upon understanding the underlying causes of LLM hallucinations. Let’s explore them in the next section.
Common causes of hallucinations in large language models
Put simply, the root cause of LLM hallucination lies in its data. Here are various ways in which data and other factors have an impact on an LLM’s performance and lead to hallucinations:
1. Inadequate data quality
Hallucinations can happen when the training data used to teach the model isn’t thorough or has limited contextual understanding that sometimes leave the model unfamiliar. For example, let’s say we’ve fine-tuned a generative model using contracts from the financial services industry. Now, if we ask it to draft contracts for real estate property or healthcare, it might struggle because it hasn’t been exposed to the specific terms and concepts in those respective sectors.
Typically, generative AI mainly aims to generate text responses based on prompts. So, even if it doesn’t fully “get” the prompt, it might still try to produce a response based on its limited training data, which can result in inaccurate outputs.
2. Overfitting
Overfitting refers to a scenario when a model becomes highly accurate with the data it was trained on but struggles with new data. When we train ML models, we aim to teach them to generalize from the training data, meaning they should be able to handle new instances effectively.
However, overfitting happens when a model gets so good at memorizing the inputs and outputs of its training data that it can’t adapt well to new information. For example, think of a model used to assess a financial portfolio. It might seem 90% accurate in evaluating assets and liabilities, but if it’s overfitting, its accuracy might drop to around 70%. Thus, when you use this model for loan decisions, you’ll likely see reduced gains and more debt.
3. Improper text encoding
LLMs transform words into sets of numbers through a process called vector encoding. This method offers some notable advantages over directly working with words. It addresses the issue of words with multiple meanings by assigning a distinct vector representation for each meaning, which reduces the risk of confusion.
For instance, the word “bank” would have one vector representation for its financial institution sense and another for its riverbank meaning. Also, vector representations help semantic operations, like finding similar words, to be expressed as mathematical operations.
Problems arising from errors in encoding and decoding between text and these representations can result in the generation of hallucinated content. Deliberately crafted prompts designed to confuse the AI can also provoke it to produce false responses.
But are all hallucinated responses so bad after all? Not always.
Is there a positive side to LLM hallucination?
Yes, depending on what you are trying to achieve with the model. If you want a story plot or another creative asset that has never been produced before, hallucination may work in your favor. In the case of a model intended to represent a subject matter expert, hallucination is harmful.
Recognizing this need to balance creativity with factual accuracy, Microsoft Bing AI provides an interesting way for users to interact with the model. It gives them three different options to converse based on their needs.
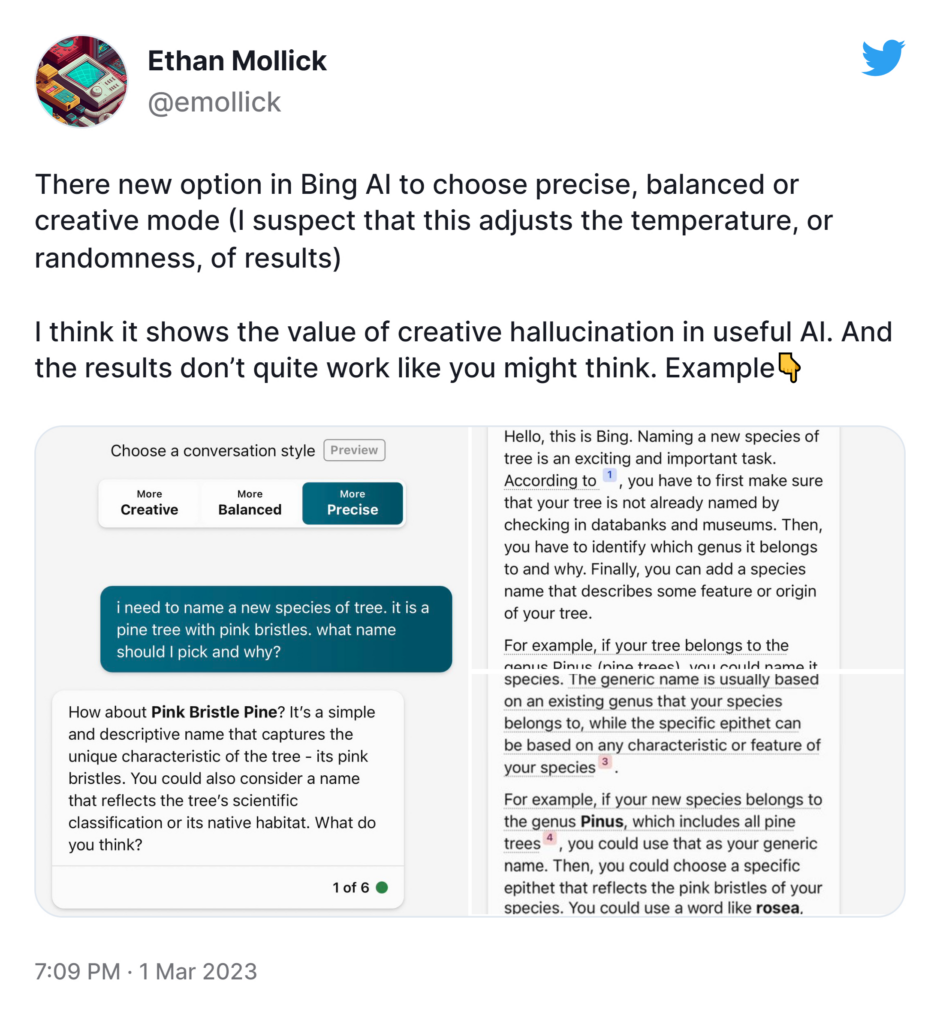
Undoubtedly, AI hallucination opens up some fascinating possibilities for creative and beneficial purposes. Here are a few examples:
- Art and Design
LLM hallucination provides a fresh path for artistic expression, giving artists and designers a tool to create visually stunning and imaginative images to spark new art forms and styles.
- Data Visualization and Interpretation
With AI hallucination, we can uncover new connections and present alternative viewpoints on complex information. It is valuable in fields like finance, where visualizing complex market trends and financial data can lead to more nuanced decision-making and risk analysis.
- Gaming and Virtual Reality (VR)
Hallucinations in large language models help develop unique immersive experiences and construct virtual worlds. Game developers and VR designers can design new domains that take user experiences to the next level. It also adds an element of surprise and wonder to gaming adventures.
Despite these use cases, LLM hallucination remains a serious problem, and businesses are on the lookout for ways to reduce these fabrications.
Effective ways for organizations to reduce LLM hallucinations
Increasing the volume of training data for LLMs doesn’t necessarily reduce hallucinations. Quality matters as much as quantity. Biased or incomplete data can lead to a higher incidence of hallucinations.
For instance, consider LIMA (Less Is More for Alignment), a fine-tuned 65B parameter version of LLaMa. LIMA’s training is based on 1,000 carefully curated prompts without reinforcement learning or human preference modeling. This approach aligns the model with specific response formats and input styles to produce higher-quality output. As a result, LIMA is less prone to hallucinations on specific tasks than LLaMa, which relies on less curated input data.
In addition to improving training data quality, here are a few tips to reduce LLM hallucinations:
1. Providing pre-defined input templates
Prompt augmentation, a technique used in machine learning, particularly with language models, can help reduce hallucinations in LLMs. It involves the use of instructions given to a model to guide its output. Create predefined prompts and question templates that guide users to structure their queries in a way that the model can understand more accurately. This helps users frame questions that are less likely to result in hallucinatory responses.
2. Adopting OpenAI’s Reinforcement Learning with Human Feedback (RLHF)
OpenAI has leveraged a technique known as reinforcement learning with human feedback (RLHF) to shape the behavior of models like ChatGPT. This approach involves regular human evaluator reviews of the model’s responses, providing feedback based on desired behavior, such as accuracy.
These human evaluations train a neural network called a “reward predictor.” This predictor scores the model’s actions based on their alignment with desired behavior. Adjustments are made to the AI model’s behavior using this predictor, and the process is iteratively repeated to improve overall performance.
3. Fine-tuning the model for specific industries
Fine-tuning an existing LLM entails integrating domain-specific knowledge into a system already proficient in general information and language interactions. This process involves tweaking specific parameters of a base model and requires far less data, often just hundreds or thousands of documents.
For example, Google trained its Med-PaLM2 model on medical expertise specifically. The project began with Google’s general PaLM2 LLM, which was later refined by retraining it using carefully curated medical knowledge sourced from various public medical databases. The result was a model that answered 85% of U.S. medical licensing exam questions, a notable improvement of almost 20% compared to the initial general knowledge-based version.
4. Using process and outcome supervision
A recent paper by OpenAI introduces two models aimed at enhancing LLM performance and reducing hallucinations. Process supervision entails a reward model that provides continuous feedback at each step, mirroring human-like thought processes. Conversely, outcome supervision trains reward models to evaluate the final output generated by the AI.
LLM hallucination is a double-edged sword
On one hand, it opens up creative possibilities in art, gaming, and other fields. However, the risks posed by unchecked false information and fabrications can’t be ignored, especially for high-stakes applications.
While no solution fully eliminates LLM hallucinations, combining careful data curation, specialized fine-tuning, and reinforcement learning with human feedback shows promise for maximizing benefits while controlling risks.
To understand how you can optimize large language models for improved accuracy, check out our blog – How to Fine-Tune Large Language Models.