Testing is a best-case scenario to validate the system’s correctness. But, it doesn’t predict the failure cases that may occur in production. Experienced engineering teams would tell you that production environments are not uniform; they’re full of exciting deviations.
The fun fact is – testing in production helps you test the code changes on live user traffic, catch the bugs early, and deliver a robust solution that increases customer satisfaction. But, it doesn’t help you detect the root cause of the failure.
And that’s why adopting observability in testing is critical. It gives you a full-stack visibility inside the infrastructure and production to detect and resolve problems faster. People using observability are 2.1 times more likely to detect any issues and report a 69% better MTTR.
This article will determine how observability can fit into software testing and QA to create a sustainable impact. So, let’s get things moving.
How observability impacts software testing?
While testing focuses on whether the particular functionality works appropriately, observability focuses on the system’s overall health. Together, they provide a holistic picture of your system.
Observability and testing are natural allies. Both help ask questions related to system or application functionality, be curious about how something works, and get into details of what went wrong.

There are two ways through which observability can help software testers:
- It help testers uncover granular details about system issues: During exploratory testing, observability can help testers find the root cause of any issues through telemetry data such as logs, traces, and metrics, helping in better collaboration among various teams and providing faster incident resolution.
- It help testers ask questions and explore the system: Testers are curious and like to explore new things. With the observability tool, they can explore the system deeply and discover the issues. It helps them uncover valuable information that assists them in making informed decisions while testing.
In the future, you may expect observability to replace traditional software testing. The focus has shifted from “Did we build the right thing?” to “How we will know when the system isn’t working”?
Testing in production and the role of observability
Traditional software testing, i.e., testing in pre-production or staging environments, focus on validating the system’s correctness. However, until you run your services inside the production environment, you won’t be able to cover and predict every failure that may occur.
Testing in production helps you discover all the possible failure cases of a system, thereby providing service reliability and stability. With observability, you can have an in-depth view of your infrastructure and production environments. You can predict the failure in production environments through the telemetry data, such as logs, metrics, and traces.
Observability in production environment helps you deliver robust products to the customers.
How to test in production?
There are two ways to conduct testing in production environments:
- A/B Testing
- Continuous Monitoring
A/B Testing: Here, you release two versions of a website or app to analyze which option user prefers the most. For example, let us assume that there are some changes made in the “Shopping Cart” of an e-commerce website.
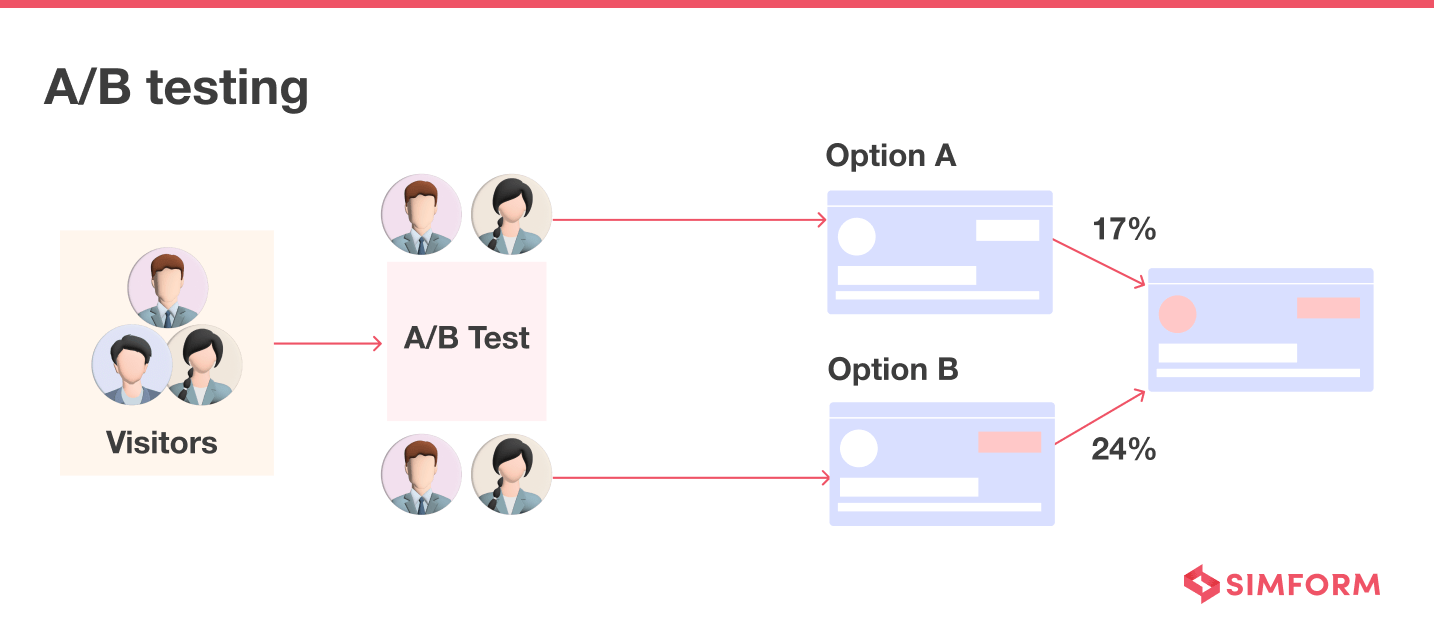
You can conduct A/B Testing to analyze if the changes lead to a higher checkout ratio by releasing two versions of “Shopping Cart”, one without changes and one with modifications. Gauge the checkout rate for both versions to know which works best for users.
A/B testing emphasizes the user experience, and with observability, you can achieve it in the end. It provides full-stack visibility inside the production environment so developers can know whether a particular feature or update would affect the user experience before release.
Continuous Monitoring: With constant monitoring of a production environment, you can discover issues with the software. For example, if you want to check the loading speed of your website pages, you should do it in production.
The pages may load very well in staging due to less traffic and smaller datasets, but you may have a different result when it goes into production with real users. Also, the results in the production are of actual use as it directly impacts the user experience.
Continuous monitoring and observability are the backbones of your CI/CD pipeline, as they help ensure the health, performance, and reliability of your applications and infrastructure across the IT operations lifecycles.
Best practices for testing in production
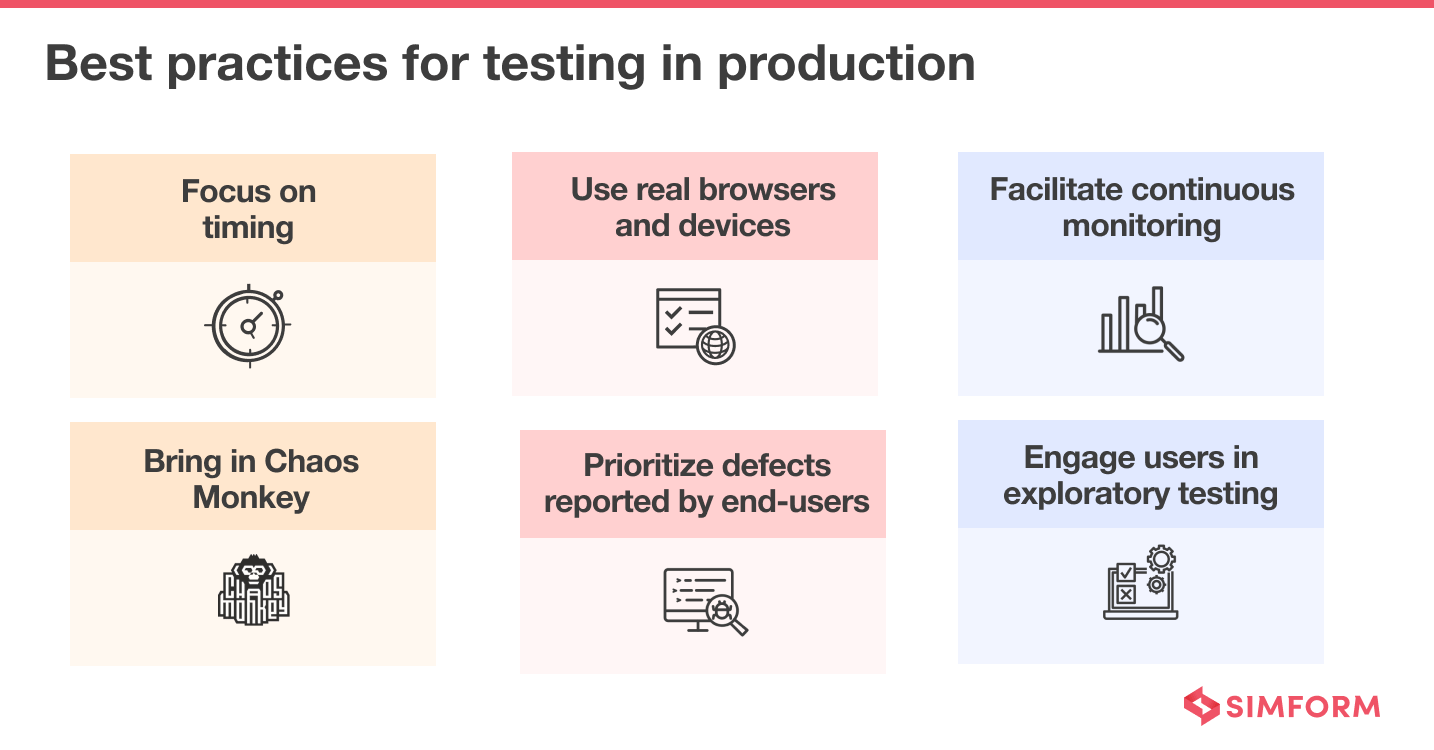
- Focus on timing: Knowing when to conduct tests in production matters a lot. A good application or production tends to retain optimum performance even with a tremendous amount of load. So, always conduct production testing under the most challenging situation, as it helps you know whether the app or product would work well with real users.
- Use real browsers and devices: The production environment must comprise real browsers, devices, and operating systems. Otherwise, you won’t get accurate insights about whether an app would work well in real-time scenarios. Furthermore, no emulator or simulator can create real-world conditions.
- Facilitate continuous monitoring: To reap the benefits of testing in production, continuous monitoring of servers and databases is paramount. Also, keep an eye on key performance metrics such as page views, uptime, latency, etc., to see whether testing the application in production has an undesirable effect on the user experience.
- Bring in chaos monkey: Chaos Monkey is a methodology coined and successfully implemented by Netflix engineers. It’s a method that randomly throws failure in the production environment to force the engineers to build more resilient and fault-tolerant services. Chaos Monkey also tests the app code for unexpected failure conditions.
- Prioritize defects reported by end-users: Accept the flaws noted by the end-users. It helps in building credibility for your enterprises. Also, prioritize the defects reported by the end-users and resolve them sooner. Lastly, if correcting the flaws is taking significant time, inform the end-users about the same. It builds trust factor.
- Allow users to engage in exploratory testing: Always announce your product’s new features or version release and ask for feedback. Conducting a beta-testing will help you discover the areas that need improvement. You can, then, work on those areas before the final product release and deliver a solution that satisfies the users’ needs.
So far, we have understood the role of observability for testing in production and their best practices. Let’s decode the three stages of testing in production environments.
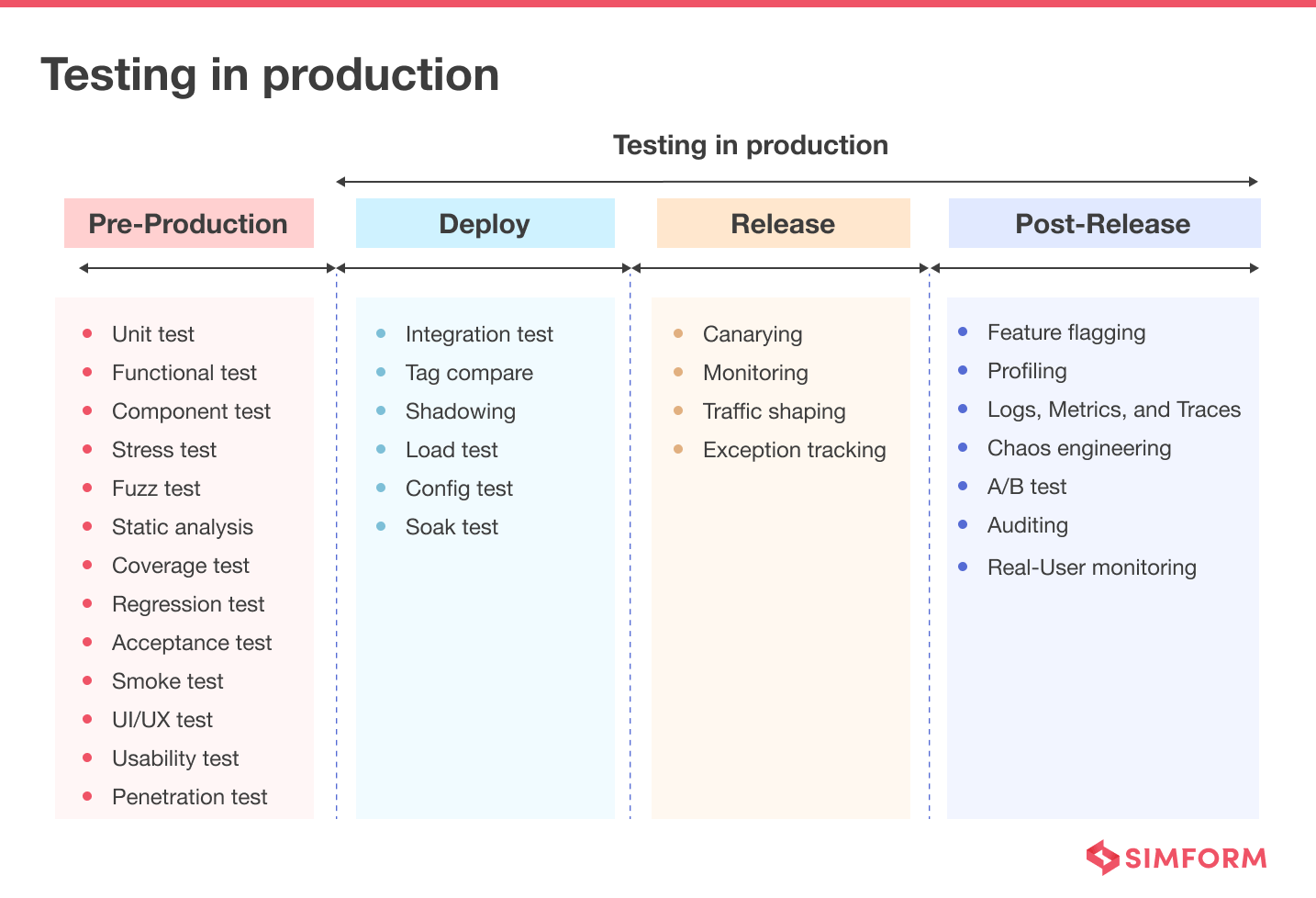
The three phases of testing in production
To better understand the role of testing in production, we can divide them into three phases:
- Deploy
- Release
- Post-Release
Phase 1: Deploy
Deployment is installing a newer version of the code on the production infrastructure. However, it doesn’t expose the newer version to the end user; it verifies whether it is good enough to handle the traffic.
To conduct testing in a production environment, it’s paramount that you run the test cases in an environment that resembles the production, and that is the production itself.
However, you should ensure that a failure during these tests doesn’t affect the end user. So, deploy a service in a production environment that doesn’t get exposed to the user immediately by conducting various tests, such as:
Integration testing
Here, you can test different units, modules, or components as a single entity to know whether interfaces between various components work as desired. If there are any defects or issues during the interaction between multiple parts, integration testing will expose those.
Nowadays, developers tend to opt for microservice architecture that comprises various components. Observability in microservices exposes system states in production so developers can detect and solve issues between various components.
Shadowing
Shadow Testing or Dark Launching allows you to test the production-ready software on a small group of users. In contrast, the end users keep using the software without the new feature.
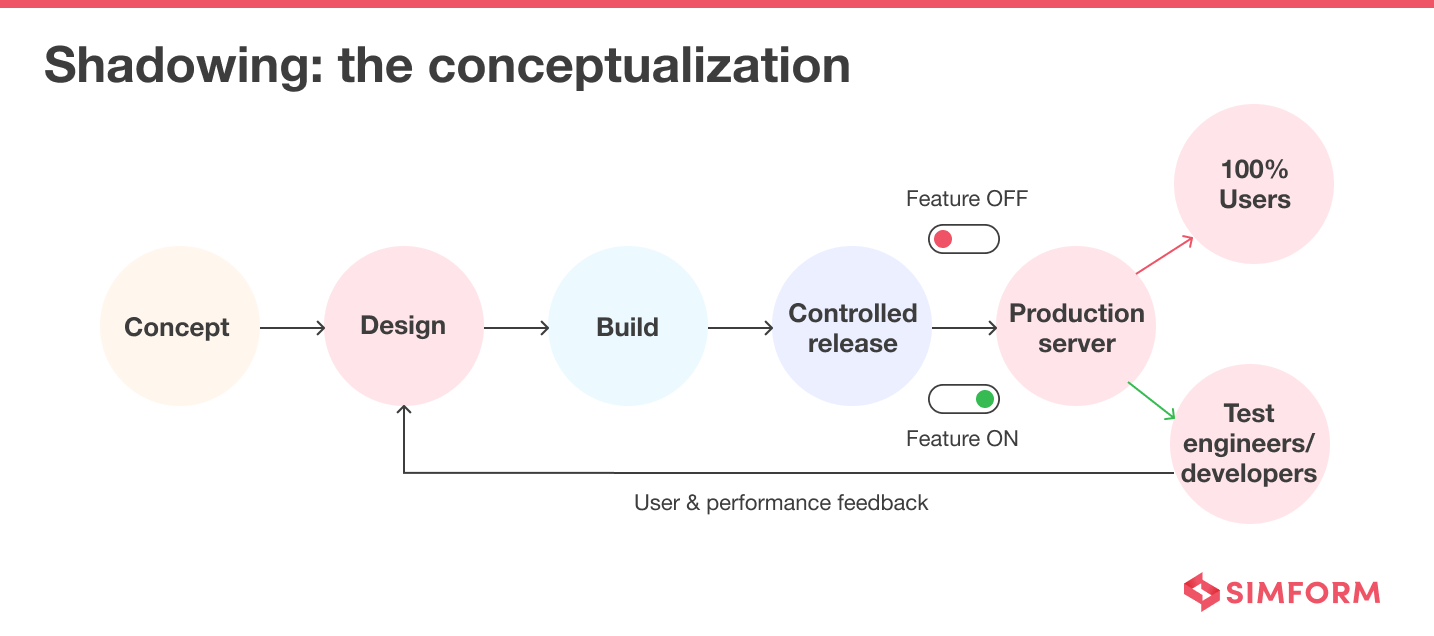
With the help of this technique, you can monitor the difference between the current environment and the environment with a new feature. It helps you reduce the risk before the final version gets released to the end users.
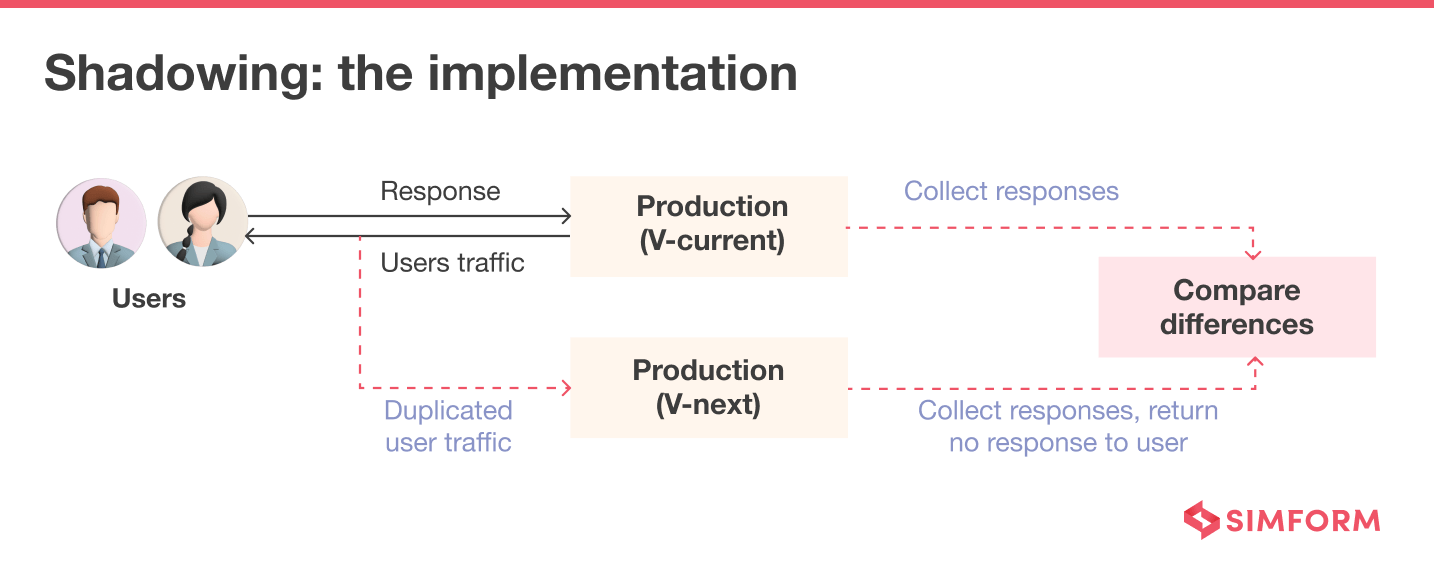
Observability, further, gives your development team the flexibility they need to test the systems in production, ask questions, and investigate issues. Developers can know whether a feature would work well or not, thereby, ensuring hassle-free release of features.
Tag compare
It’s a technique to verify the correctness of a newer implementation of the existing system. The tag-compare tool replays a sample of production traffic against the new system and compares it with the current system. So you can find and fix any issues without exposing bugs to end users.
By adopting observability, you can test a newer version of your system in the production environment and monitor resiliency and have insights about how customers would receive it. You can also know whether it’s good to move to a newer implementation or stay with the current system for a while and fix the bugs in the newer version.
Load testing
It’s a technique to determine a system’s behavior under normal and peak load conditions. You can also identify the maximum operating capacity of an app and determine its peak capacity to handle concurrent users. The ultimate goal of load testing is to improve performance bottlenecks and ensure stability.
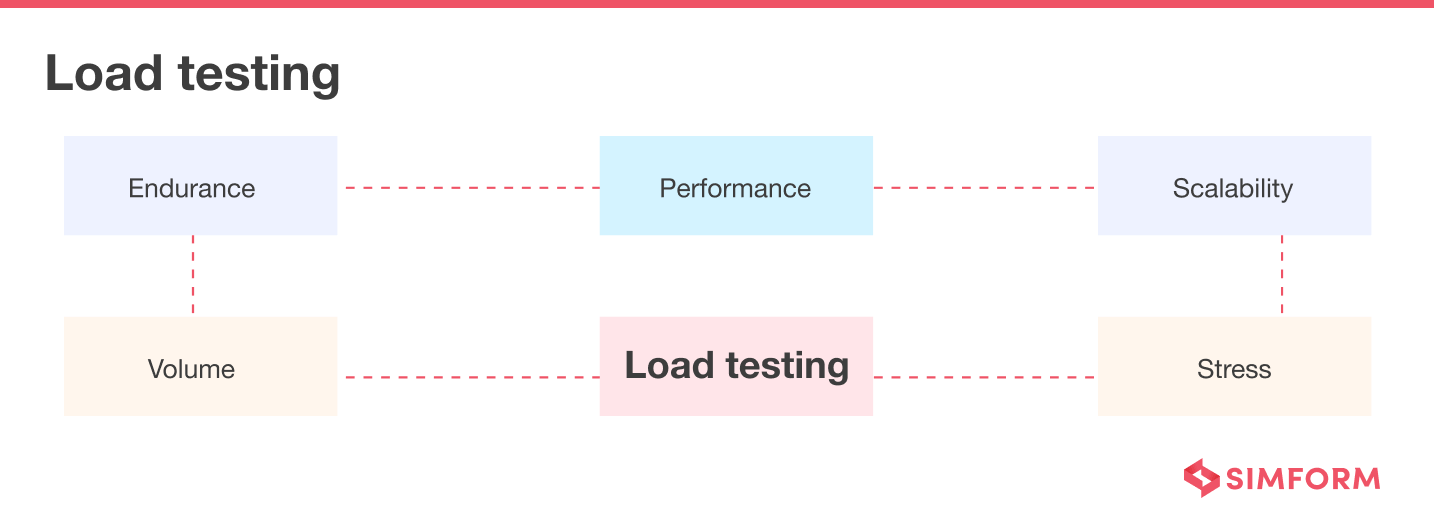
Observability systems continuously collect performance data from across distributed IT environments and correlate it in real-time. Based on that data, developers know how much load it can handle well in advance. Developers can also determine the system’s peak capacity, so observability facilitates load testing.
Phase 2: Release
When we say the product is released, we move production traffic to the newly deployed version. All the risks related to shipping, i.e., outages, angry customers, snarky write-ups, etc., come under the release phase.
A bad release of any software can become the reason for a partial or complete outage. The release is also the phase where you may perform a rollback of a new service if it’s proving unstable.
Now, let us explore various test types that come under the release phase.
Canarying
Canary Testing refers to testing a new software version or feature with real users in the live production environment. You can reduce the risk of release with this technique as it emphasizes slow or incremental rollout.
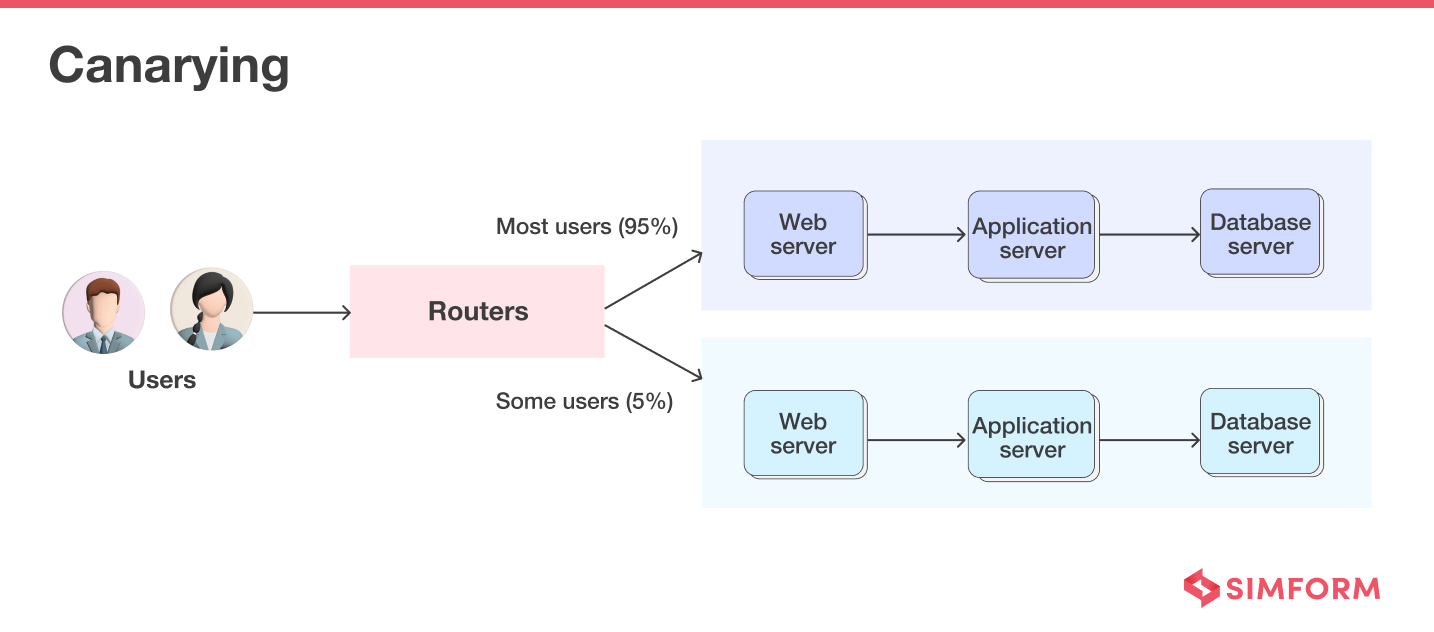
You generally roll out the new version or feature to only a small set of users referred to as “Canary,” and once you become confident with the release, you add more users. Also, if anything goes wrong, you can quickly roll back and rectify errors, as the user base is small.
With observability, you can have full-stack visibility inside production, which is crucial to understand the quality of the canary version you release. It readily assesses whether the new version is ready for wider deployment. You can even implement a blue/green deployment strategy with observability, one of the canarying techniques.
Monitoring
It’s one of the must-have techniques for every production rollout and release. Monitoring helps you know the overall health of your IT systems. However, “monitoring everything” is ineffective; you should decide on some core metrics or KPIs to analyze the IT systems accurately.
Monitoring tells you whether something is wrong, while observability enables you to understand why. Monitoring is a subset of and key action for observability.
Exception tracking
It’s a technique to get insights into the production environment and identify problems as early as possible. You can find the root cause of the performance issues by tracking and monitoring various exceptions.
Observability allows developers to get visibility into the production environment to record, investigate, and resolve issues related to any exception. It can conduct the root cause analysis of exceptions to ensure a smooth product release.
Traffic shaping
It’s a bandwidth management technique that delays some or all datagrams to improve latency, optimize performance, or increase usable bandwidth. So, Traffic Shaping aims to ensure a higher QoS (Quality of Service) for a business’s network traffic.
Network observability uses diverse data sources to understand what is happening inside a network and how the internal state of the network impacts business objectives and user experience.
Phase 3: Post-Release
The post-release phase follows after a successful release, where you focus on debugging and monitoring rather than pure testing. You try to continuously observe the systems and gather analytics to check whether they’re working correctly.
Here’s what you can test in this phase
Feature flagging
It’s a method in which developers wrap a new feature in an if/then statement to gain more control over the release. With this mechanism, developers can isolate the effect of a new feature from the entire system. It separates the feature rollout from the code deployment.
Observability also works on a similar principle, allowing you to know in advance whether a particular feature would work under an actual production environment load. Before including that feature in the final release, you can get an idea of its workability.
Logs, metrics, and traces
- A log is an immutable human-readable form record of a historical event.
- A metric is a numeric value measured over a specific period and contains attributes such as timestamps, KPIs (Key Performance Indicators), and values.
- A trace represents an end-to-end request journey right through the distributed systems.
Observability measures a system’s current state based on logs, metrics, and traces
Profiling
It helps you diagnose the problems related to performance. For implementation, you may need to add a single line of code or require significant instrumentation. Profiling and metrics together provide a statistical overview of a system’s health and track events over time.
Observability is a technique that focuses on identifying issues related to performance and availability to provide a holistic view of the system’s health.
Chaos engineering
This is a technique of experimenting with a distributed system to make it reliable and resilient. Netflix was the first to popularize the concept of Chaos Engineering when it introduced the idea of Chaos Monkey.
It focuses on –
- Injecting error conditions to verify the fault-tolerance capabilities of the system
- Forcing a misbehave in the network to see how the service reacts
- Killing random nodes to verify the system resilience
Observability facilitates the idea of Chaos Engineering as it implements shift-left trace-based testing that continuously checks whether the integration of a new version or feature harms the current production environment. It also alerts the developers about any issue in production and prompts them to take appropriate action. So, the final version is robust, reliable, and resilient.
Wish to incorporate observability into your ecosystem?
We, at Simform, can help you adopt observability within testing just like we helped auction houses.
As the engineering team was adding new features to white-labeled cloud native solution, there was a need for constant cloud monitoring to detect and fix bugs quickly. Our team, then, adopted observability within testing to identify bugs faster and resolve them in a distributed environment. It helped the client to reduce delivery time and ensure a quick release to market.
Similarly, you can collaborate with our engineering team and avail a solution that transforms your business.